install.packages("Rcmdr", dependencies = TRUE)2 Uso de GUI’s
2.1 Introducción
Una GUI (Graphical User Interface) es una interfaz que permite interactuar con la parte elemental de un software. En este caso, que estamos tratando sobre R, una GUI permitira poder interactuar con la Consola y comandos R agregando una capa de visualización adicional que puede enfocarse en potenciar las funcionalidades de codificación o también, minimizar la necesidad de codificar poniendo a disposición ventanas, menús y botones que faciliten tareas específicas como la importación de datos, análisis descriptivos, visualización de datos, entre otros.
Es muy frecuente que en softwares de código abiero existan muchos proyectos alrededor buscando generar alternativas o mejoras en el uso del software, así como también ofrecer un servicio adicional al software (de paga). Esta es una breve lista de GUI’s existentes en R:
- R Commander
- Jamovi
- R AnalyticFlow
- RKWard
- Rattle: Para minería de datos
- JGR: Basado en Java
- Deducer
2.2 R Commander
Esta GUI es una de las más conocidas y usadas en R, desarrollado por el profesor John Fox de la McMaster University en Canadá. Las versiones iniciales del paquete datan del 26 de mayo de 2003, siendo lanzada su primera versión estable el 19 de abril del 2005. Desde entonces su uso empezó a incrementar cada vez más ante la escasa disponibilidad de alternativas más amigables para codificar en R que la propia Consola. No fue hasta alrededor del año 2009 donde Rstudio empezó a formularse y desarrollarse para disponerse públicamente mas adelante.
Así, R Commander mostró una gran manera de integrar el uso de la codificación en R y una interfaz gráfica que podía encargarse de tareas esenciales, y otras más avanzadas, con la facilidad de clicks en ventanas y botones, además de traducir todo ello en código que podía ser registrado. Para poder usar esta GUI, será necesario ingresar a R o Rstudio e instalar el paquete Rcmdr
Si no tenemos demasiados paquetes instalados en nuestro entorno, notaremos que al ejecutar dicho comando en la Consola, vendrá consigo la instalación de muchos paquetes adicionales que se usa al interno del software. Pese a ello, es probable que al momento de cargar por primera vez el paquete (library("Rcmdr")) observemos lo siguiente:
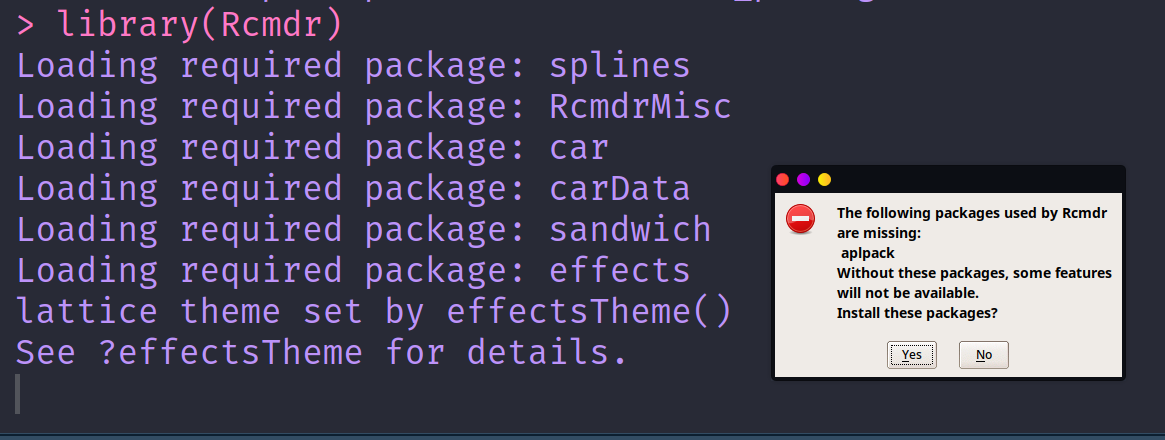
Lo cual significa que hay algunos paquetes que falta instalar para que todo funcione sin problemas. La mejor opción es instalar en ese mismo momento esos paquetes faltantes, aunque si se elige no hacerlo, R Commander seguirá funcionando hasta que llegue a requerir explícitamente el uso de ese paquete.
Una vez que se pueda cargar el paquete sin problemas, automáticamente se aperturará una ventana adicional que corresponderá a la interfaz propiamente de R Commander, y lucirá de la siguiente manera:
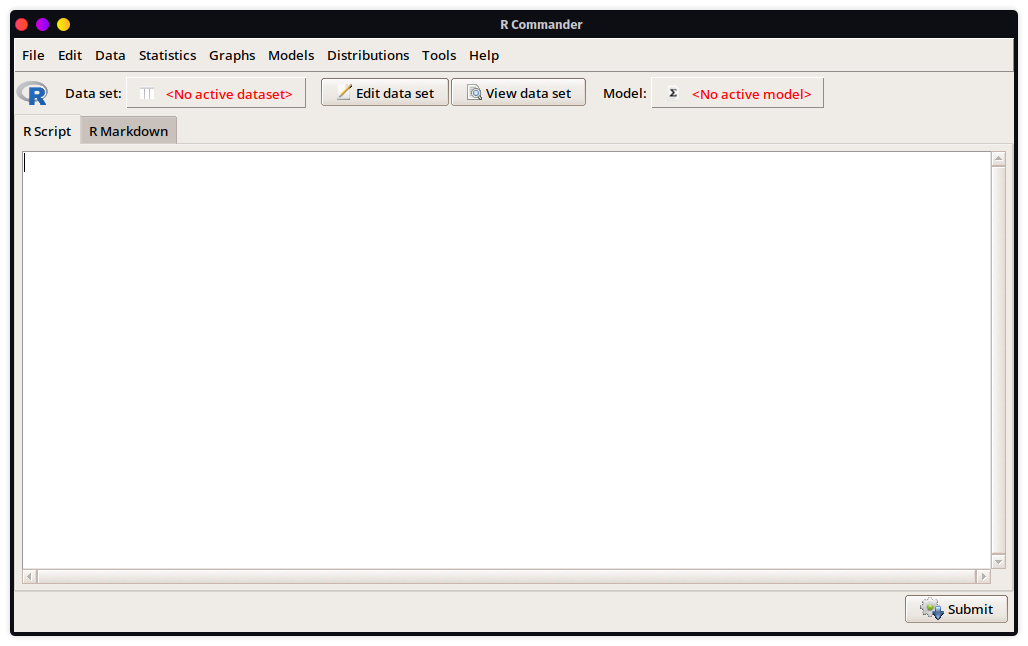
Nota
Es importante recordar que R Commander es un paquete que se está cargando en un sesión de R activa y esto trae algunas consecuencias:
- Si se cierra la instancia R donde se haya abierto (R terminal, R GUI, Rstudio, etc.), la ventana de R Commander también se cerrará.
- Todos los objetos (por ej. base de datos) que se importen en R Commander estarán disponibles en la sesión de R, incluso al cerrar esta GUI. De similar forma, si en la sesión de R tuviéramos 3 base de datos cargadas y posterior a ello se carga
Rcmdr, entonces esas 3 base de datos estarán disponibles en la GUI para su uso si se desea. - Dado que la apertura de la GUI implica una gran cantidad de configuraciones previas en función del sistema operativo así como la carga de distintos paquetes, si se cierra la ventana de R Commander, no se podrá volver a abrir a menos que se reinicie la sesión de R y se vuelva a cargar el paquete
library("Rcmdr").
2.2.1 Características
Algunas características relevantes que permite el uso de R Commander son:
- Carga de datos
Desde el menú de opciones se puede elegir cargar datos que ya se encuentren en paquetes, o cargar dentro de la misma sesión de R datos que se encuentren alojados en archivos de texto, portapapeles, archivo SPSS, SAS, Minitab, STATA o Excel. También en la última opción del menú se podrá observar la opción Manage variables in active data set que permite hacer un manejo elemental de datos: calcular, recodificar, renombrar, eliminar variables, y otras opciones de interés adicionales.
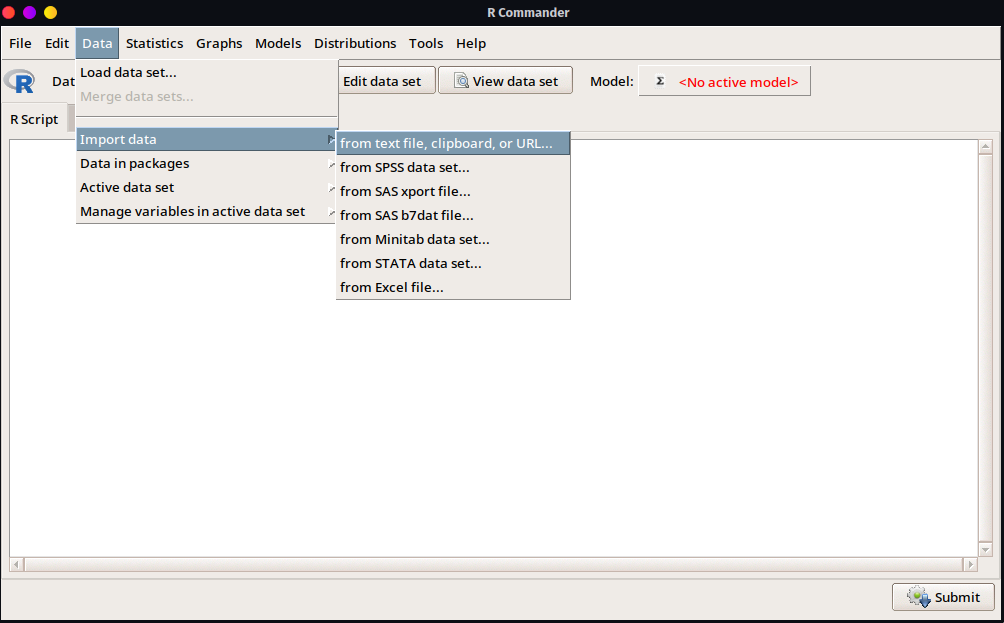
- Análisis de datos
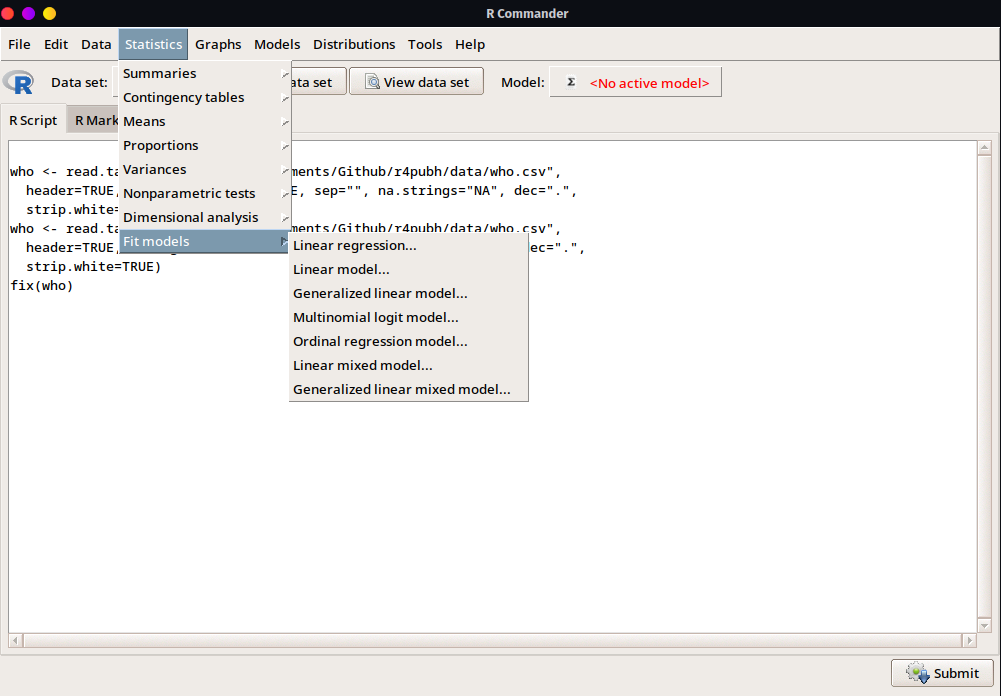
En cuánto al análisis de datos se dispone de una gran variedad de opciones entre básicas-elementales hasta algunas otras relativamente avanzadas, que permitirán ajustar modelos estadísticos, análisis paramétricos y no paramétricos y también, análisis descriptivos en los datos tal y como se observa en la Figura 2.4.
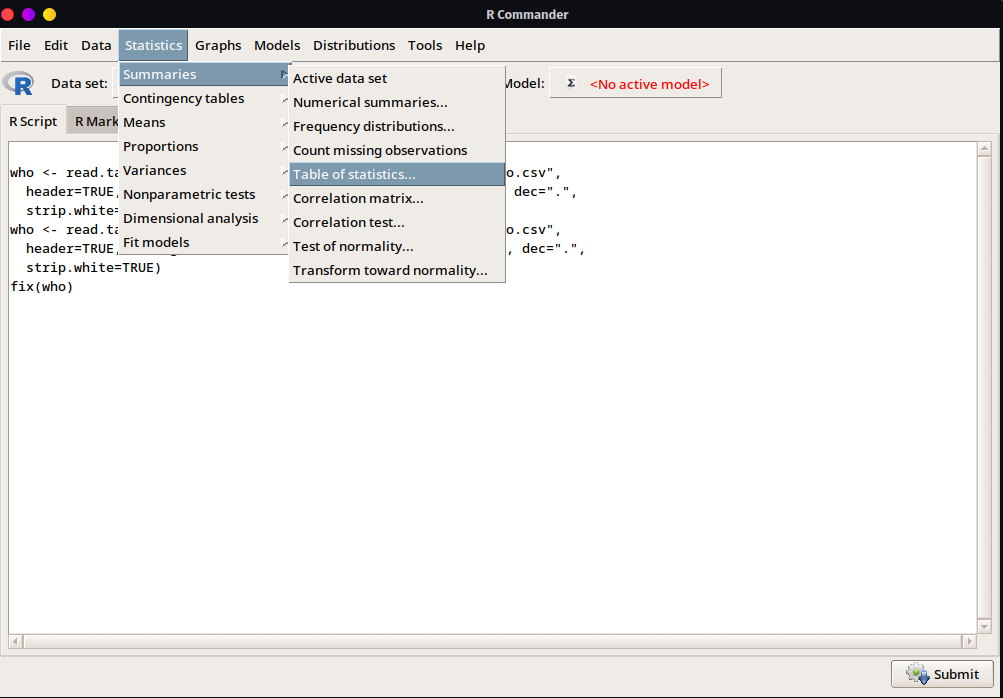
- Visualización de datos
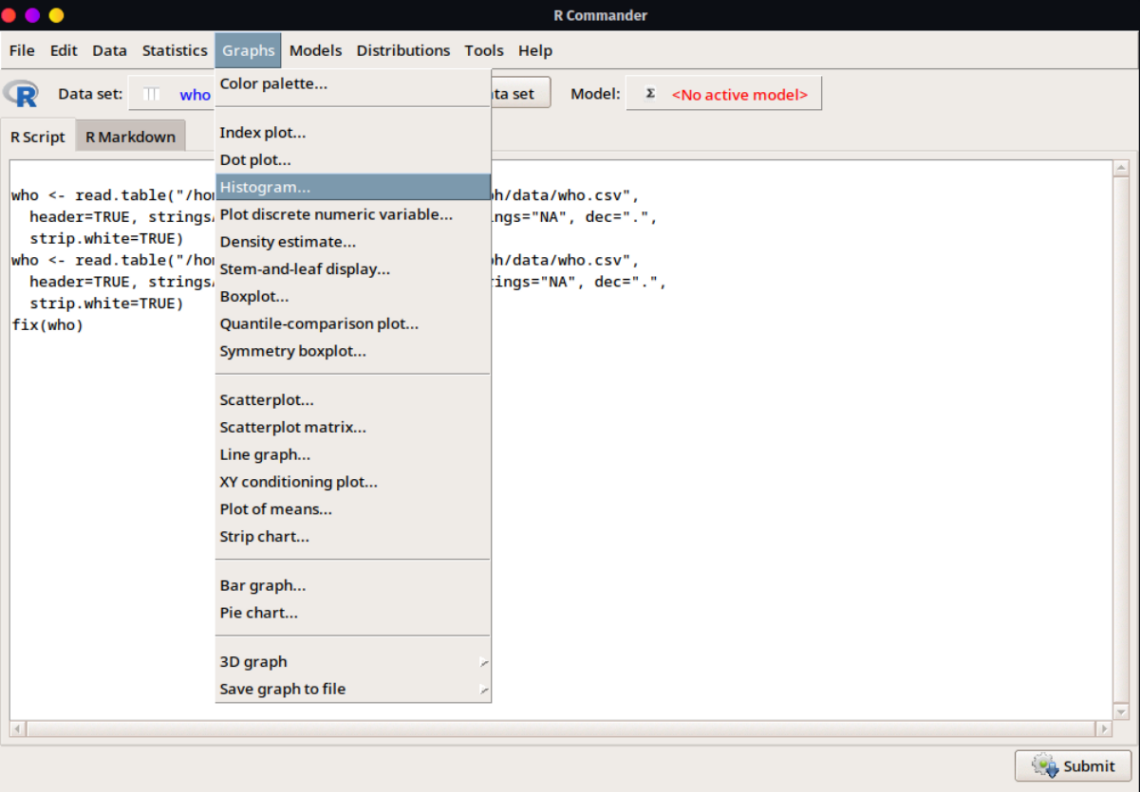
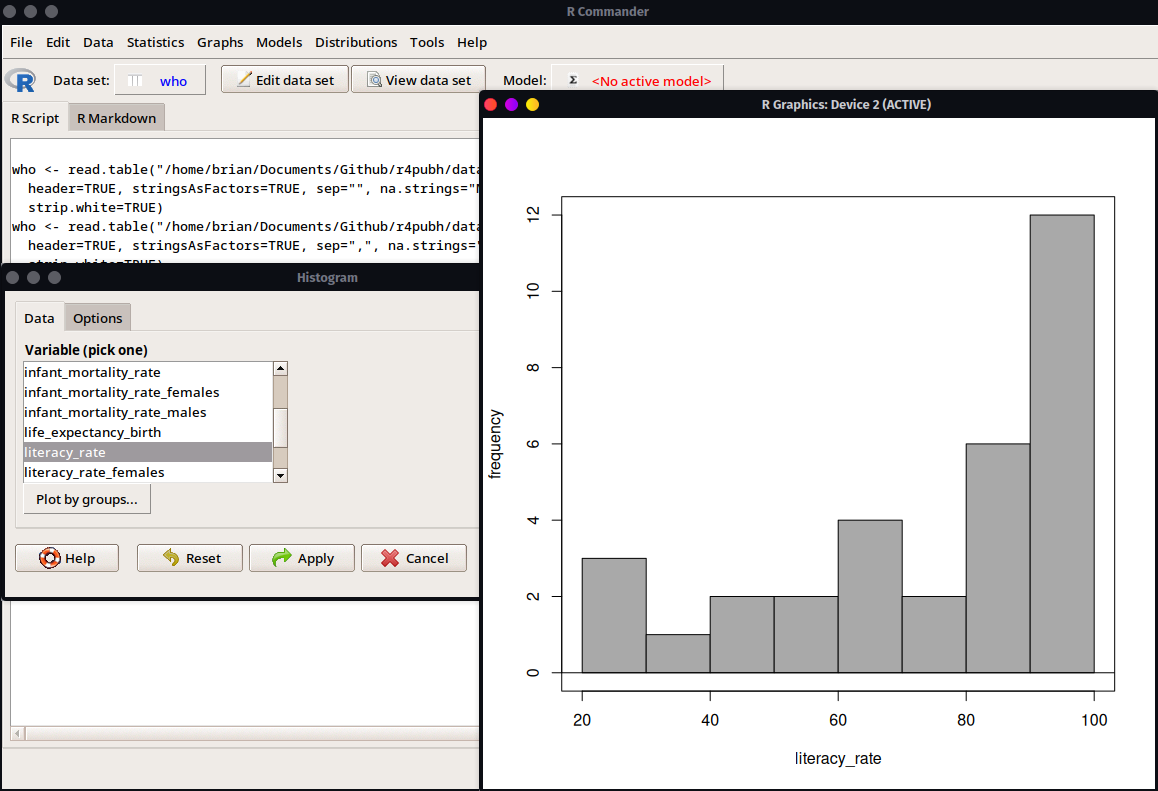
En cuánto a la generación de gráficos también se observa una gran variedad de opciones desde los gráficos básicos como histograma, boxplot, dispersión, barras, líneas, hasta algunos más complejos o incluso en 3D.
2.2.2 Ejemplificación
Veamos algunos ejemplos de análisis con R Commander. Para ello, usaremos la base de datos de la investigación de Landrigan et al. (1975) recuperado a través de Rosner (2015): lead.csv. Esta base de datos contiene registros para estudiar el efecto de la exposición al plomo en el bienestar psicológico y neurológico de 124 niños.
2.2.2.1 Prueba t de student
Realizaremos un análisis t de muestras independientes (pueden ver su desarrollo en R en la sección de Prueba t), para comparar los coeficientes de inteligencia (iqf) de acuerdo a si pertenecen al grupo de exposición a plomo o no.
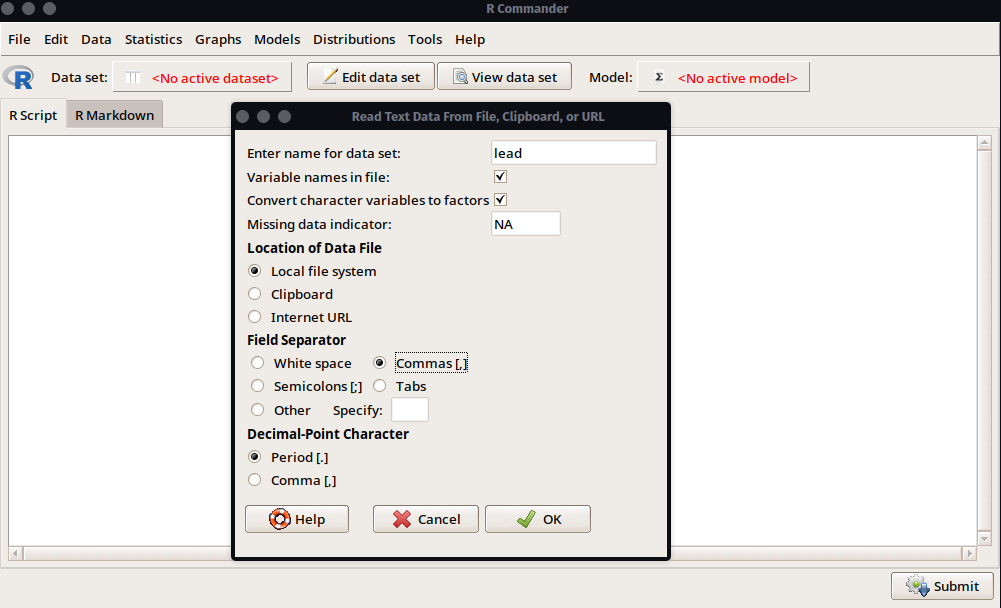
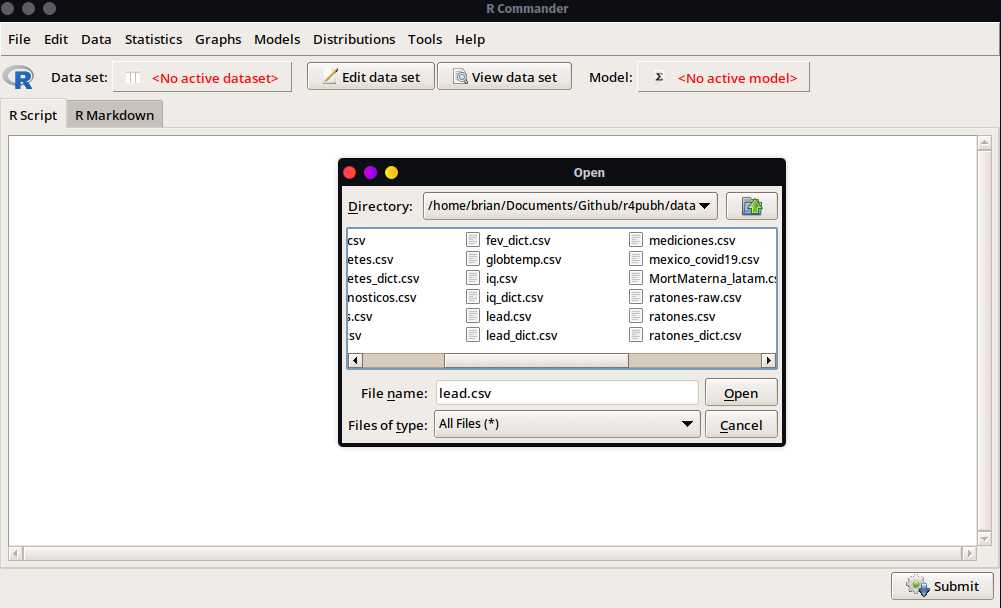
- Para realizar la importación de datos, seguiremos la ruta mostrada en Figura 2.3. En la ventana de configuración deberemos especificar el nombre que le daremos al conjunto de datos a cargar (lo dejaremos en
lead), y algunas otras opciones que dependerán del tipo de archivo que se tenga. En el caso de los archivos.csvla configuración más común es que se utilicen las comas (,) como separadores de campo, por lo que seleccionaremos ello antes de continuar seleccionandoOK.
Una vez indicado OK se pedirá seleccionar los datos en la ubicación del archivo. Seleccionamos y damos click en Open. Podremos observar que ahora aparece el nombre de la base de datos a lado de Data set:. Además, si damos click en View data set podremos observar la estructura de los datos, así como editar celda por celda si damos click en Edit data set.
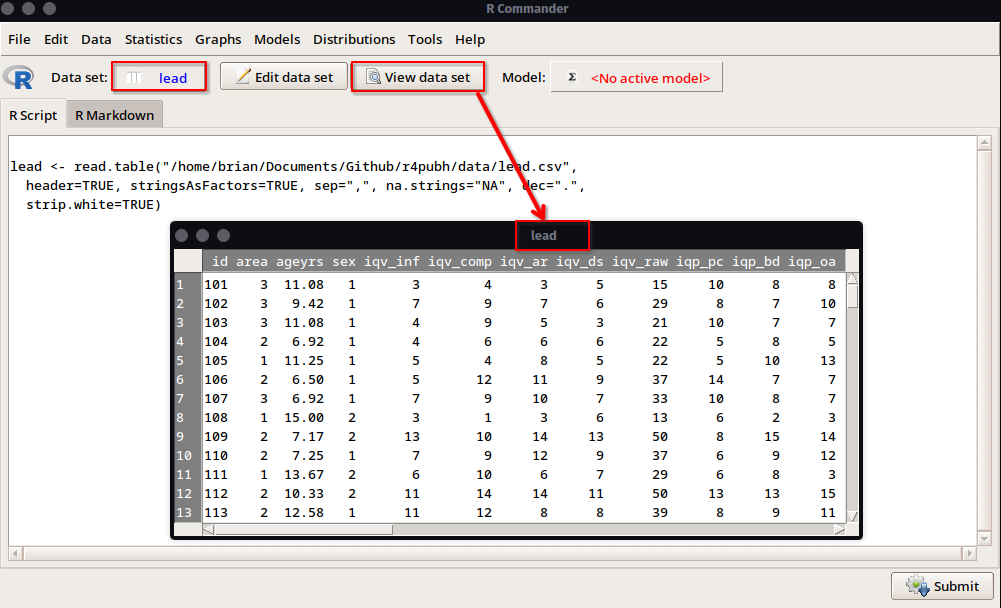
lead.csv en R Commander
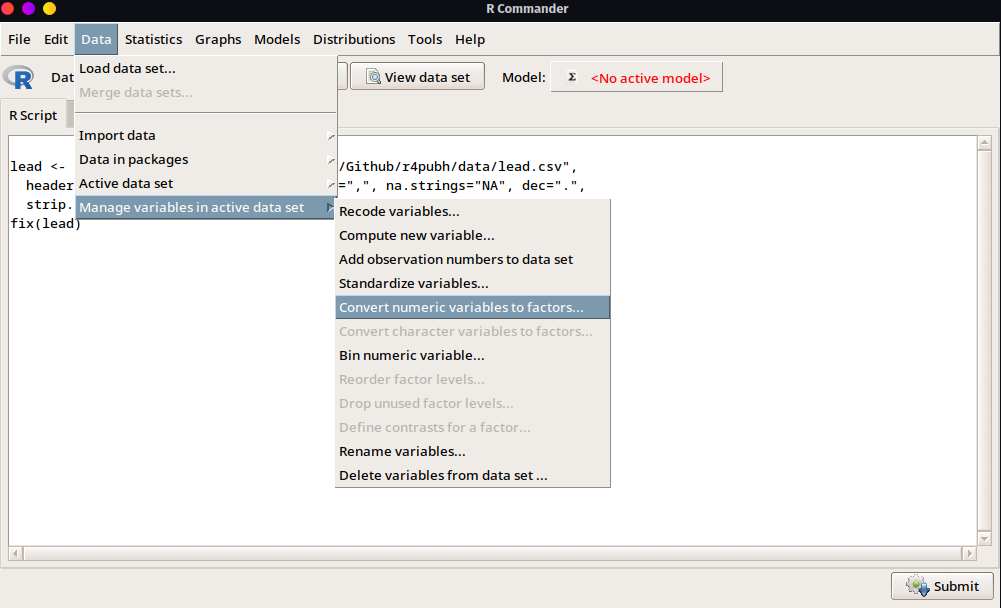
- Para poder realizar las comparaciones de los coeficientes de inteligencia
iqfen el grupo de niños expuestos al plomo en contraste a quienes no, necesitamos configurar la variableGroupcomo factor ya que actualmente se encuentra como numérica.
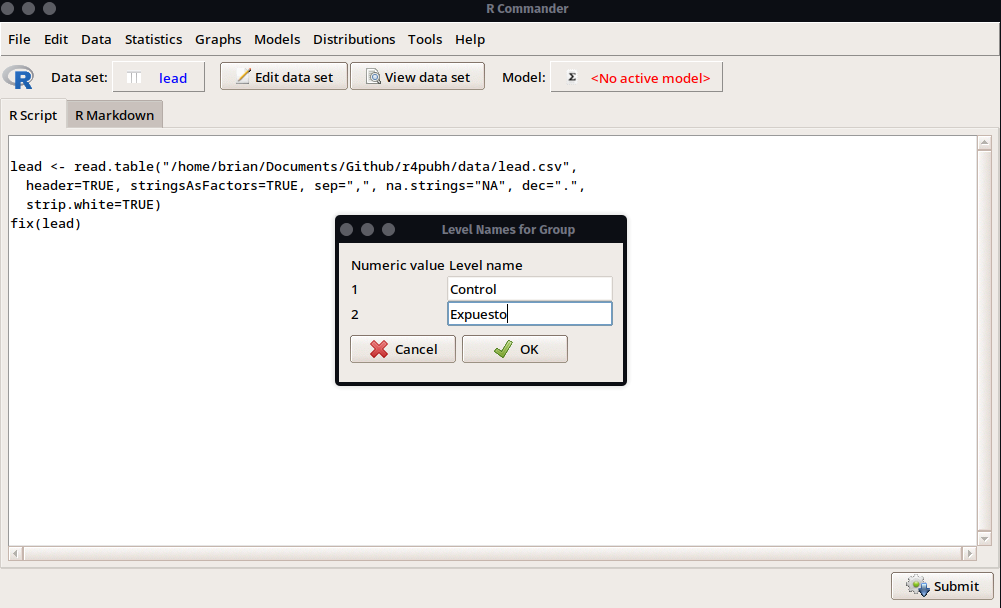
En la ventana de opciones seleccionaremos la variable Group y la opción Supply level names que nos permitirá darle una etiqueta a los niveles del factor, donde 1 será el grupo Control; y 2, el grupo Expuesto.
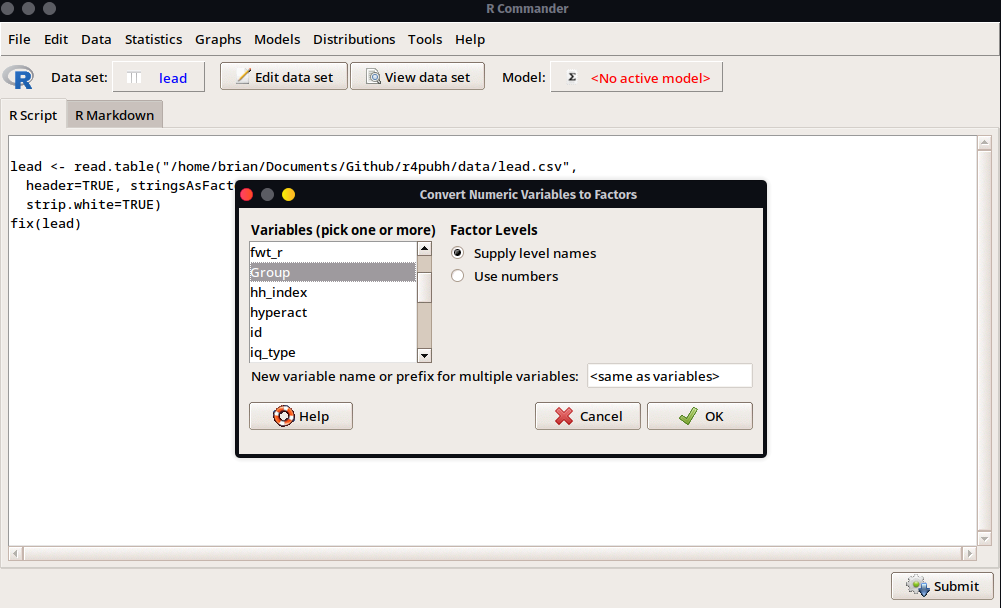
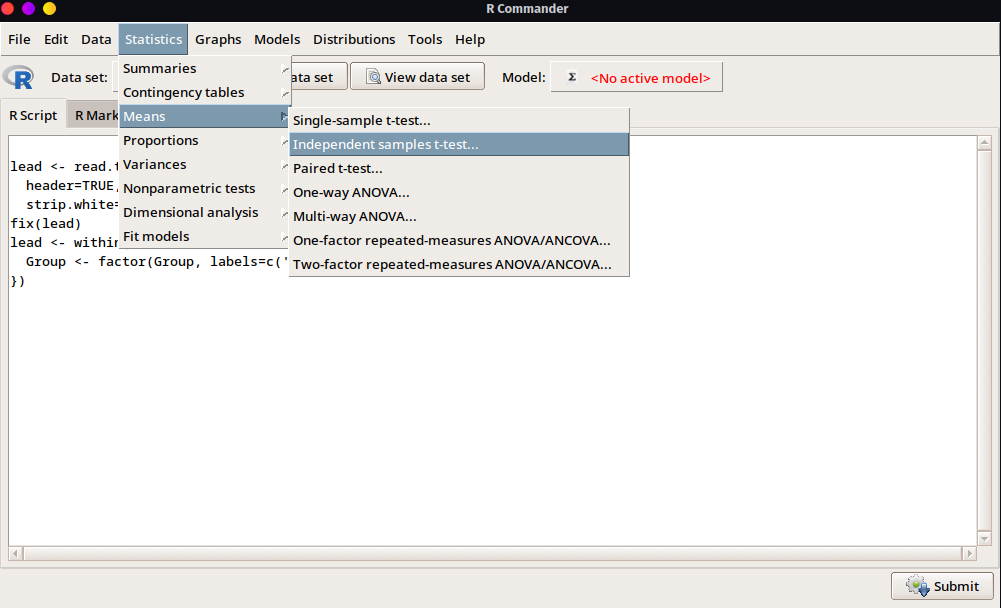
- Ahora con la configuración previa, podremos observar que el Menú
Statistics > Means > Independent Sample t-test...ya se encuentra habilitado (debido a que tenemos al menos una variable como categórica [factor]).
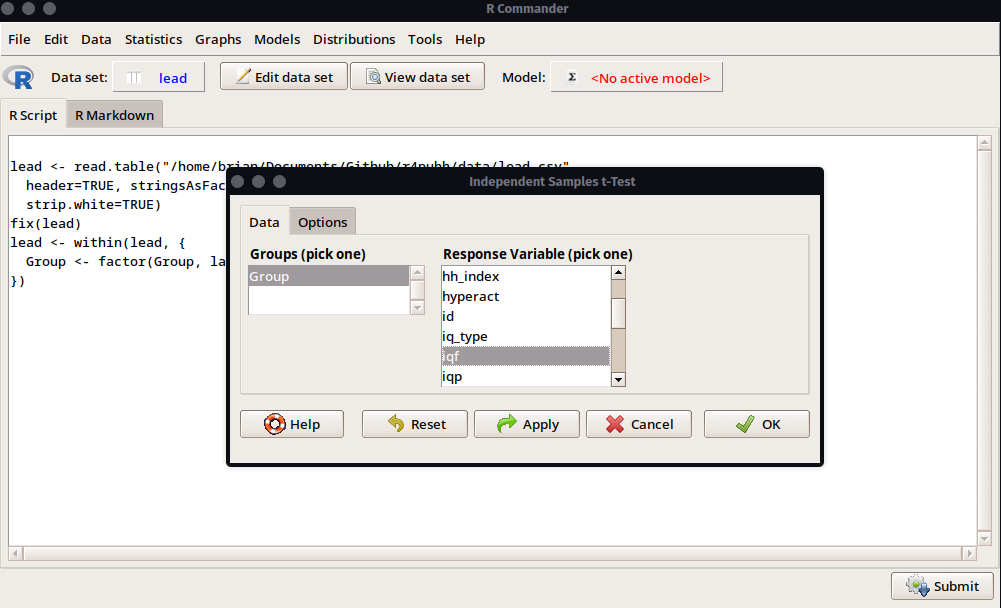
Ahora, en la ventana veremos que la variable Group ya se encuentra automáticamente seleccionado debido a que es la única que tenemos como factor. En el lado derecho seleccionaremos la variable contínua que se usará para la comparación, que en este caso será iqf que es el coeficiente de inteligencia. Adicionalmente, en la pestaña Options podremos configurar si el análisis es de 2 colas, el nivel de confianza y la asunción de la varianza entre los grupos a fin de utilizar la prueba t de Student o la t de Welch.
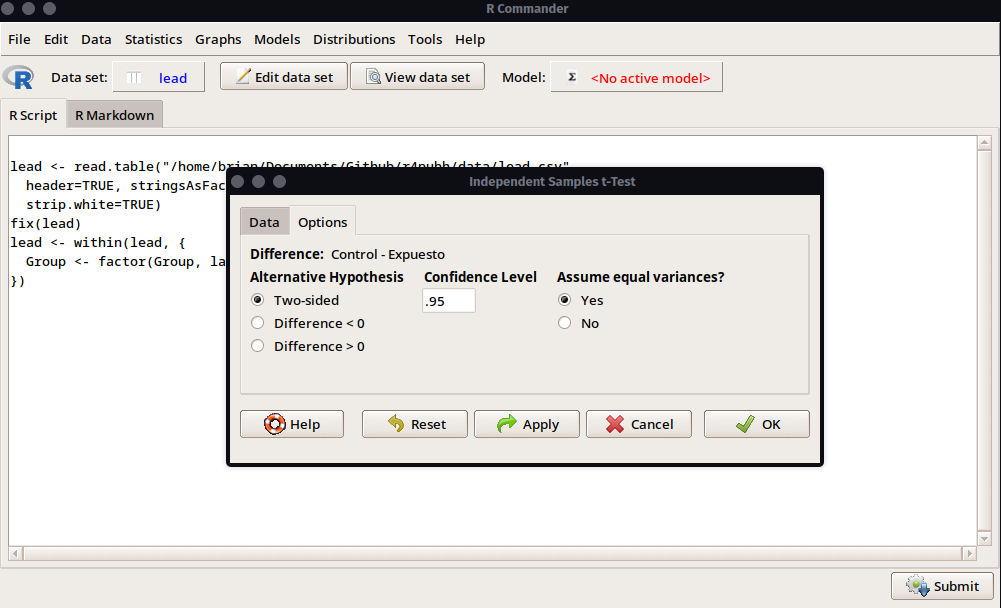
Finalmente, obtenemos los resultados que indican que a pesar de que las estimaciones de las medias muestrales (medidas descriptivas) presentan ciertas diferencias a favor del grupo control, la hipótesis nula no llega a ser rechazada (p = 0.069), por lo que no hay evidencia estadística suficiente para señalar diferencias significativas entre las puntuaciones de inteligencia.
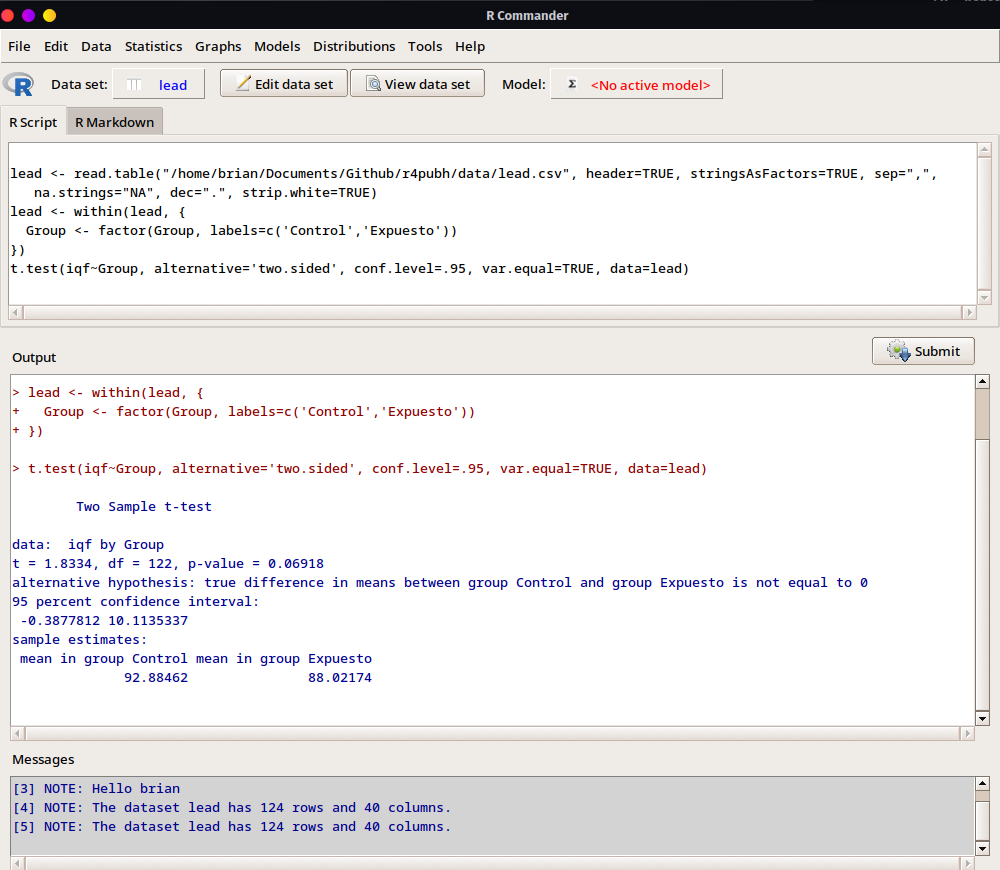
2.2.2.2 Análisis de Regresión
Para ejemplificar el desarrollo de este análisis con R Commander, seguiremos utilizando la base de datos lead que ya se encuentra cargada en el entorno (Figura 2.7). Seguiremos un objetivo de análisis similar, esta vez explicando el coeficiente de inteligencia iqf en función del nivel de plomo en la concentración en sangre de los niños (ld73).
- Para desarrollar este análisis seguiremos la ruta
Statistics > Fit models > Linear regression.
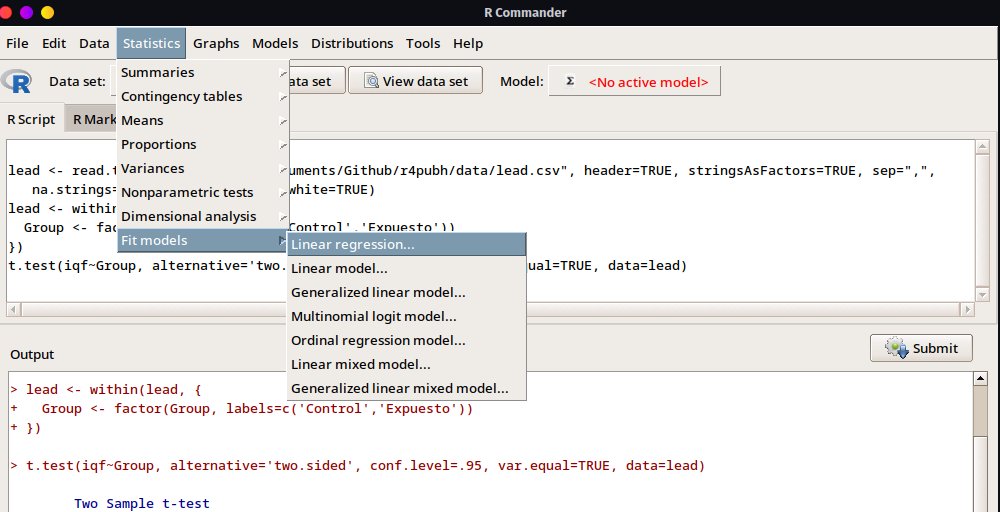
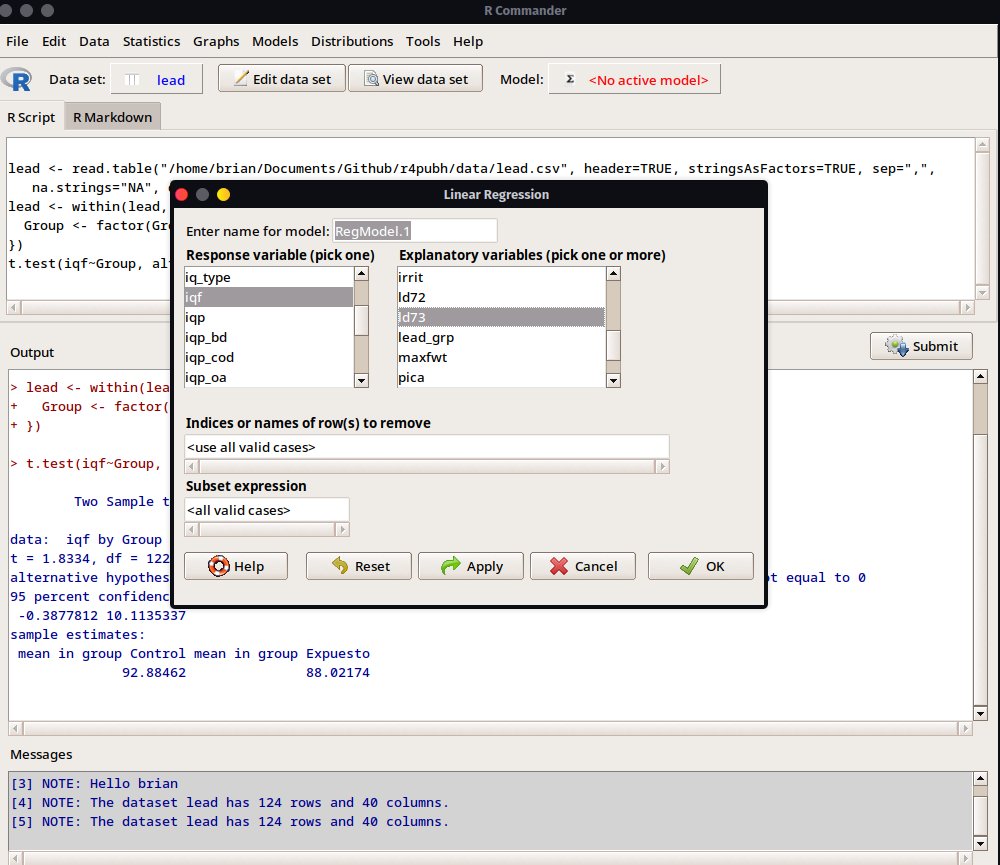
- En la siguiente ventana seleccionaremos la variable de respuesta o la variable que va a ser explicada/predicha que en nuestro caso sería
iqfy al lado derecho, seleccionaremos la o las variables que sean las explicativas/predictoras, en nuestro caso seleccionaremos solo ald73.
- Finalmente, obtenemos el resultado del análisis. Se observa que aunque hay una relación negativa entre mayor presencia de plomo en sangre y menor coeficiente de inteligencia, esta asociación no es estadísticamente significativa. Además, el modelo a penas llega a un 0.3% de varianza explicada.
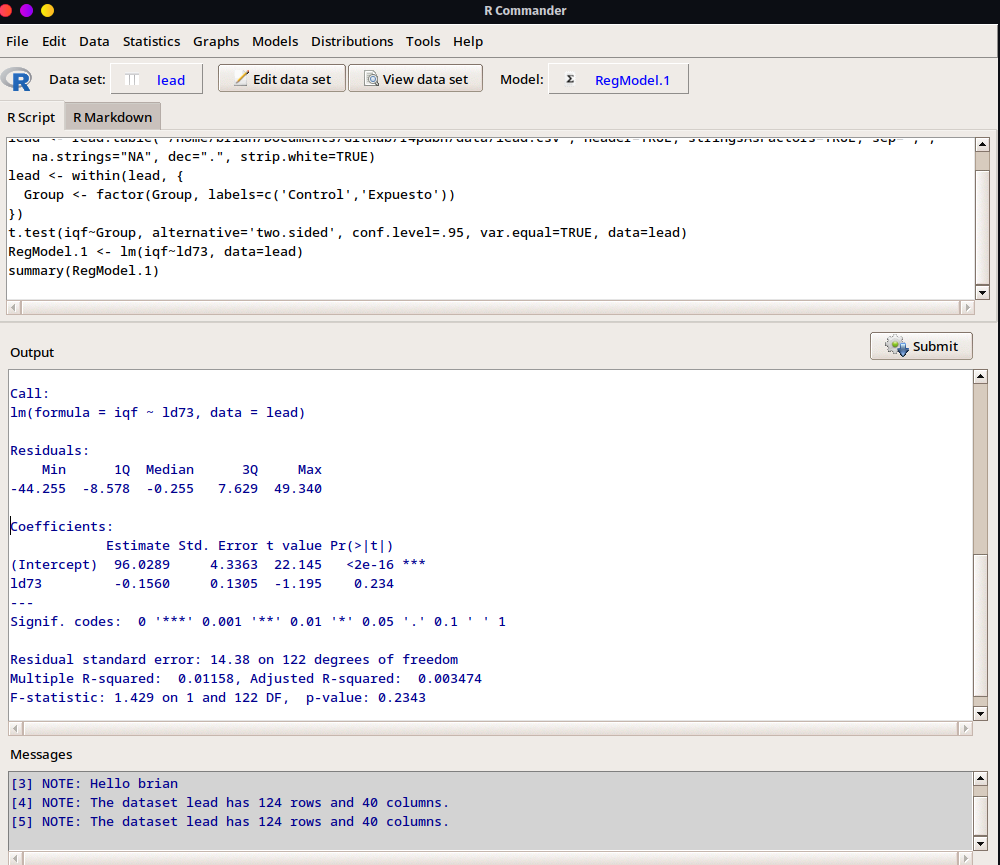
2.2.2.3 Visualización
Para explorar la distribución iqf en los grupos de ld73, realizaremos un gráfico de dispersión (scatterplot) desde R Commander.
- Para este fin buscaremos en el menú de
Graphsque contiene una gran variedad de gráficos de interés. En nuestra caso, eligiremos la opción deScatterplot...
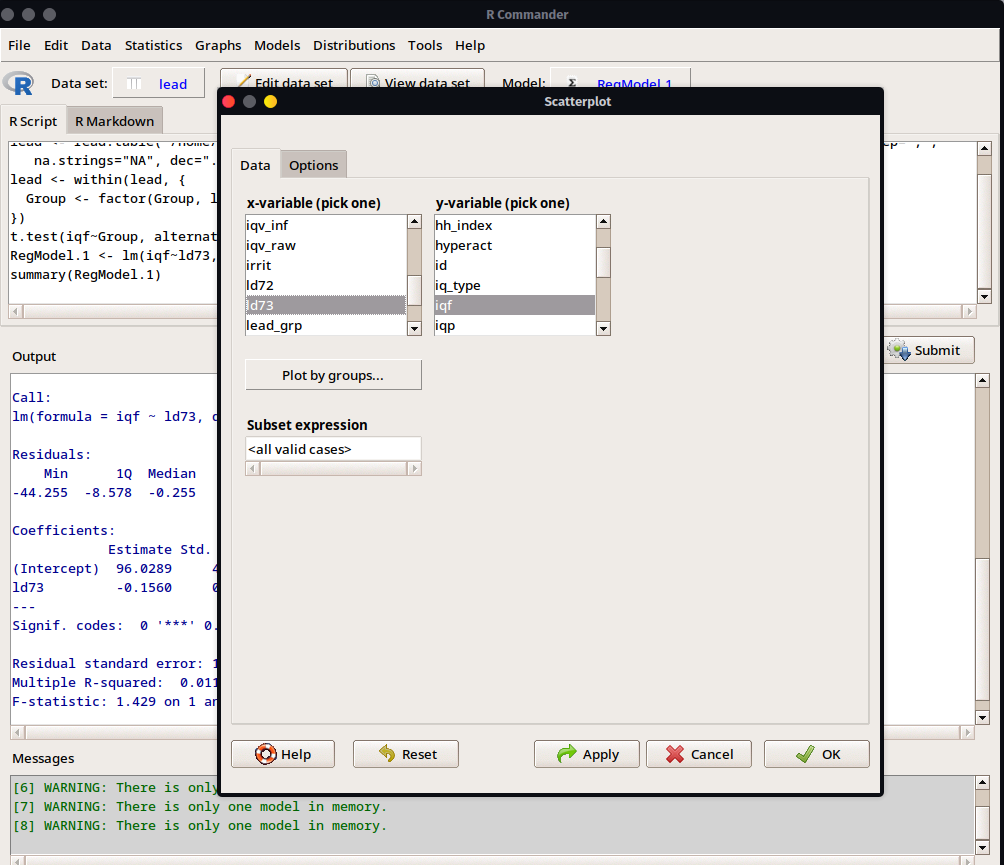
- Una vez seleccionado, se apetura una nueva ventana donde indicaremos la variable
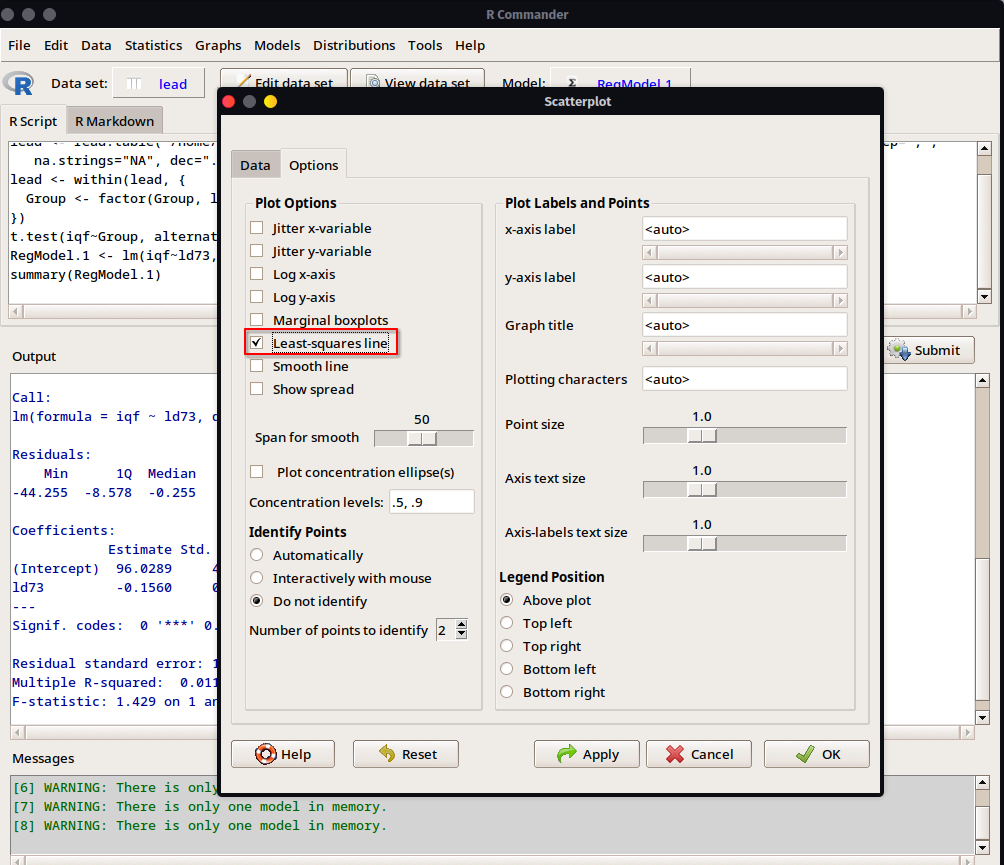
xy la variableyen el gráfico Seleccionaremos como la variablexa la explicativald73y la variableya la explicada/predichaiqf. También en la pestaña deOptionshay diversas alternativas de configuración para el gráfico como indicar el texto en los ejex, título del gráfico, posición de la leyenda y algunos otros añadidos. Seleccionaremos la opciónLeast-squares lineque insertará la línea de regresión en el gráfico.
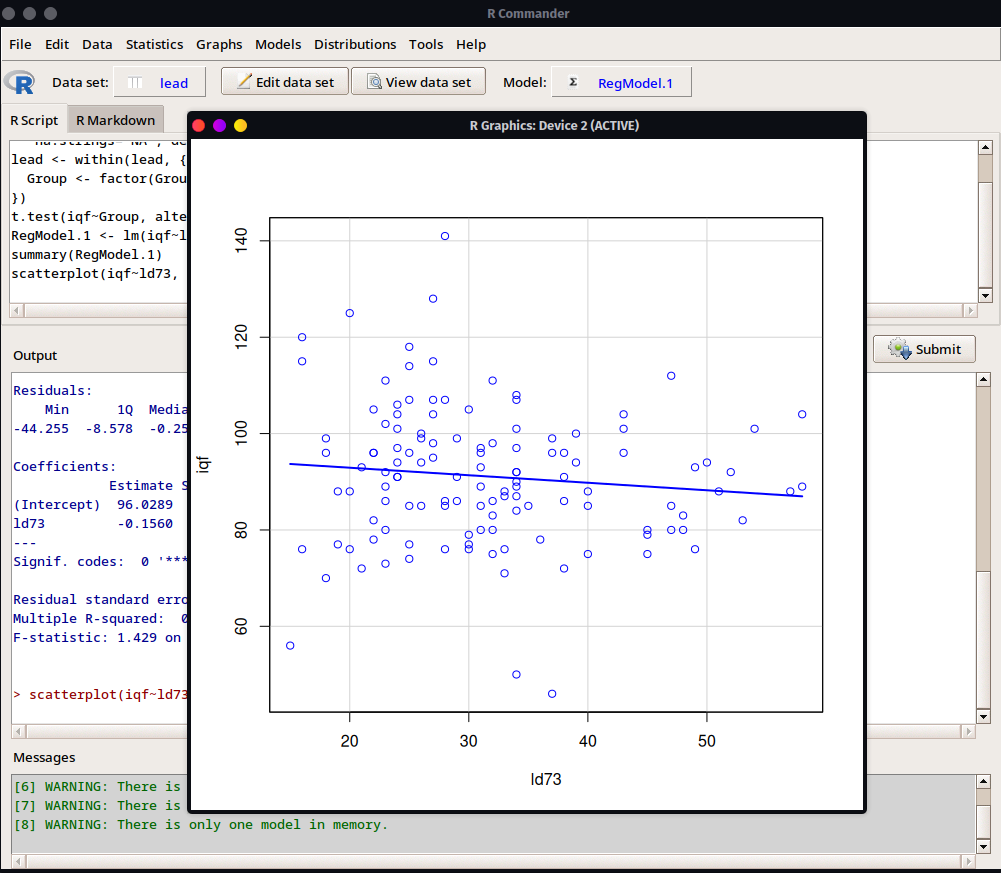
- Finalmente se obtiene el gráfico en el que podemos observar una ligera tendencia inversa entre ambas variables. Sin embargo, hay muchos valores u observaciones que se alejan considerablemente de la recta ajustada. En el rango de 20 a 30 de la variable
ld73(plomo en sangre) hay fluctuaciones de más de 60 puntos en la variableiqf(coeficiente de inteligencia), por lo que la fuerza de asociación se muestra débil.
Nota
Para una revisión más extensa sobre el uso de R Commander se recomienda el libro de John Fox (2016) llamado “Using the R Commander: A Point-and-Click Interface for R”

2.3 Jamovi
Jamovi es otra alternativa GUI multiplataforma para el uso de R en análisis de datos, pero con una interacción con líneas de código menor. Puede ser ideal para quienes están empezando a tener contacto con software de análisis o estudiantes con quienes se debe desarrollar clases de análisis de datos con un tiempo ajustado.
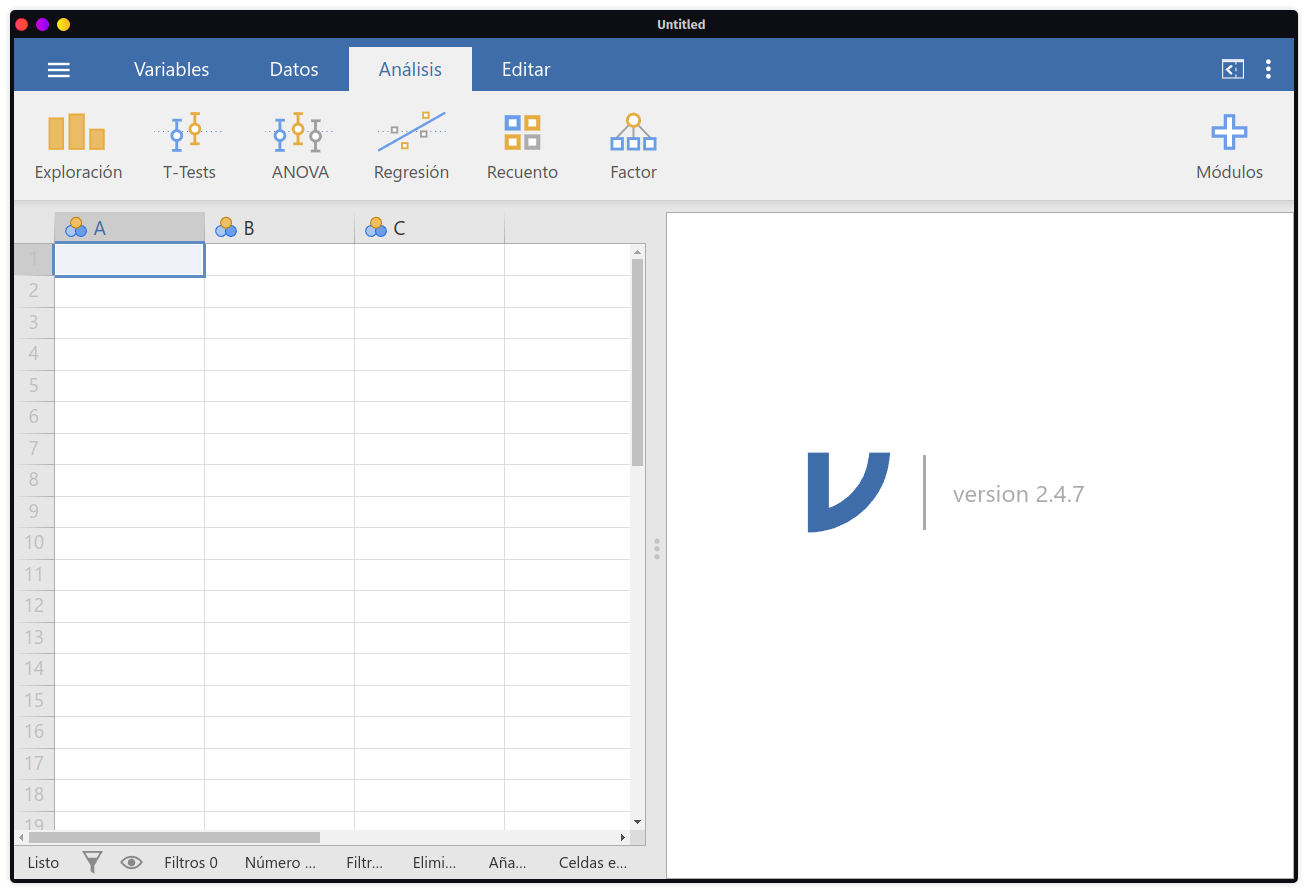
Al abrir el programa se aprecia como un software amigable con menús de análisis organizados en función del proceso que se vaya a seguir: exploración de datos, t-test (pruebas de comparación de grupos), anova (comparación de 3 a más grupos, se incluye Kruskal Wallis), regresión (correlaciones, binomial, multinomial, ordinal), recuento (proporciones, tablas de contingencia), factor (análisis de fiabilidad, factorial exploratorio y confirmatorio), y una opción más a la derecha llamada Módulos.
2.3.1 Características
Algunos aspectos relevantes a señalar en Jamovi:
- Importación de datos
El menú de importación de datos de Jamovi es bastante intuitivo y soporta algunos formatos principales de almacenamiento de datos además de sus propios formatos (.omv y .omt): archivos .csv, .json, hoja de cálculo de libreoffice .ods, de excel (.xlsx), archivos SPSS (.sav, .zsav, por), STATA (.dta), SAS (.xpt y .sas7bdat) y del mismo R (.RData y .RDS).
Además, en la misma sección de abrir datos (importación), dispone de una biblioteca de datos que contiene base de datos de ejemplo o de práctica que se pueden usar para fines de entrenamiento o comprobar el funcionamiento de ciertos análisis.
- Análisis de datos
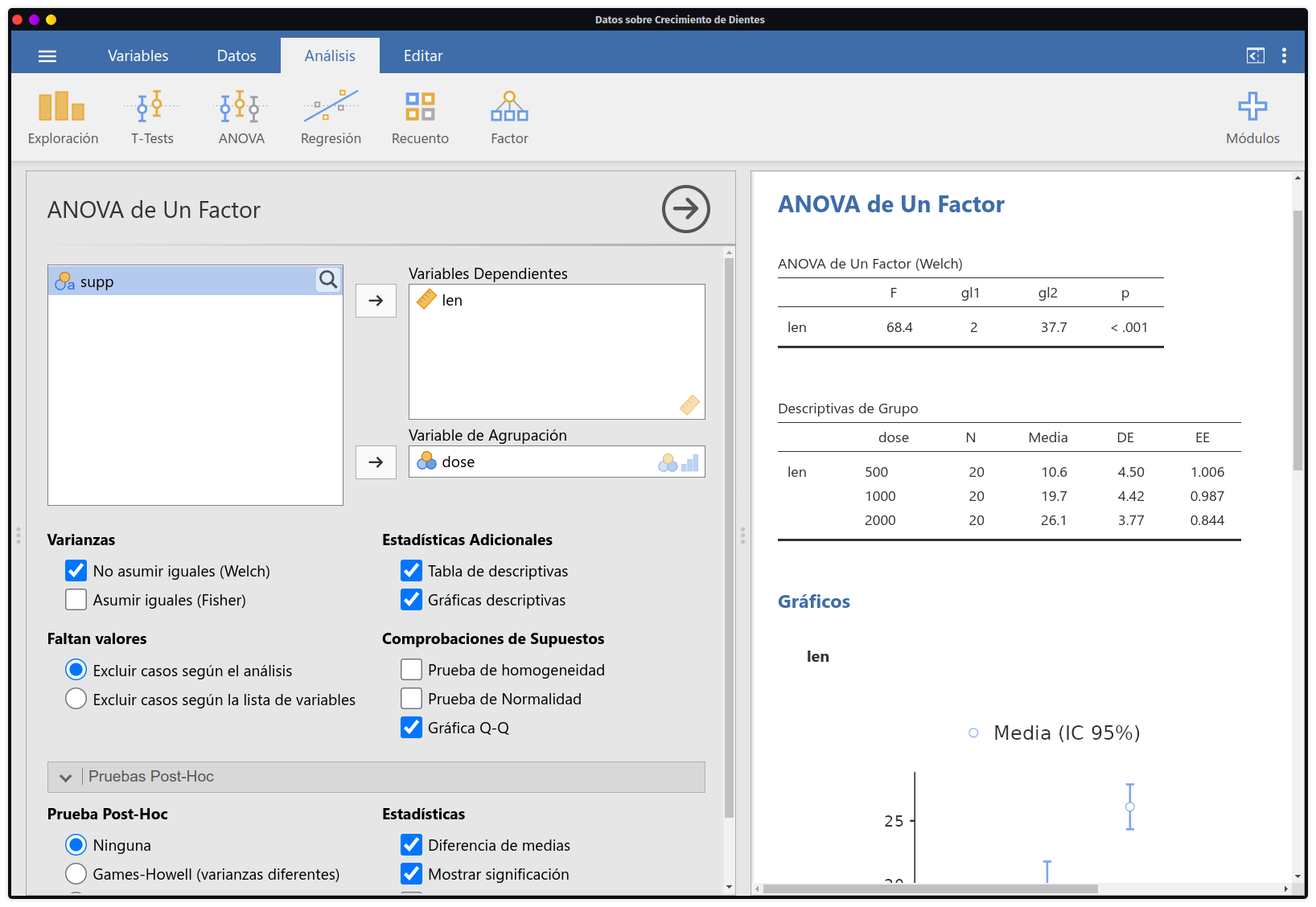
Jamovi soporta una gran cantidad de análisis de datos esenciales como los mencionado en la sección inicial de este software. Todos sus análisis siguen una misma línea de ejecución y visualización que trata de un menú de opciones donde se indica las variables de interés y todos los análisis pertinentes al tipo de proceso que se vaya a desarrollar: descriptivos, comprobación de supuestos, gráficos, tamaño del efecto, post-hoc’s, etc.
- Módulos de análisis
Jamovi cuenta con un apartado de colaboración en comunidad donde cualquier desarrollador puede incluir análisis o variaciones de análisis en Jamovi desde una tienda de módulos. Así las posibilidades de análisis en el software crecen considerablemente. Actualmente existen más de 40 módulos de análisis distintos y algunos más especializados que otros para diferentes fines y objetivos que el usuario puede disponer haciendo click en instalar.
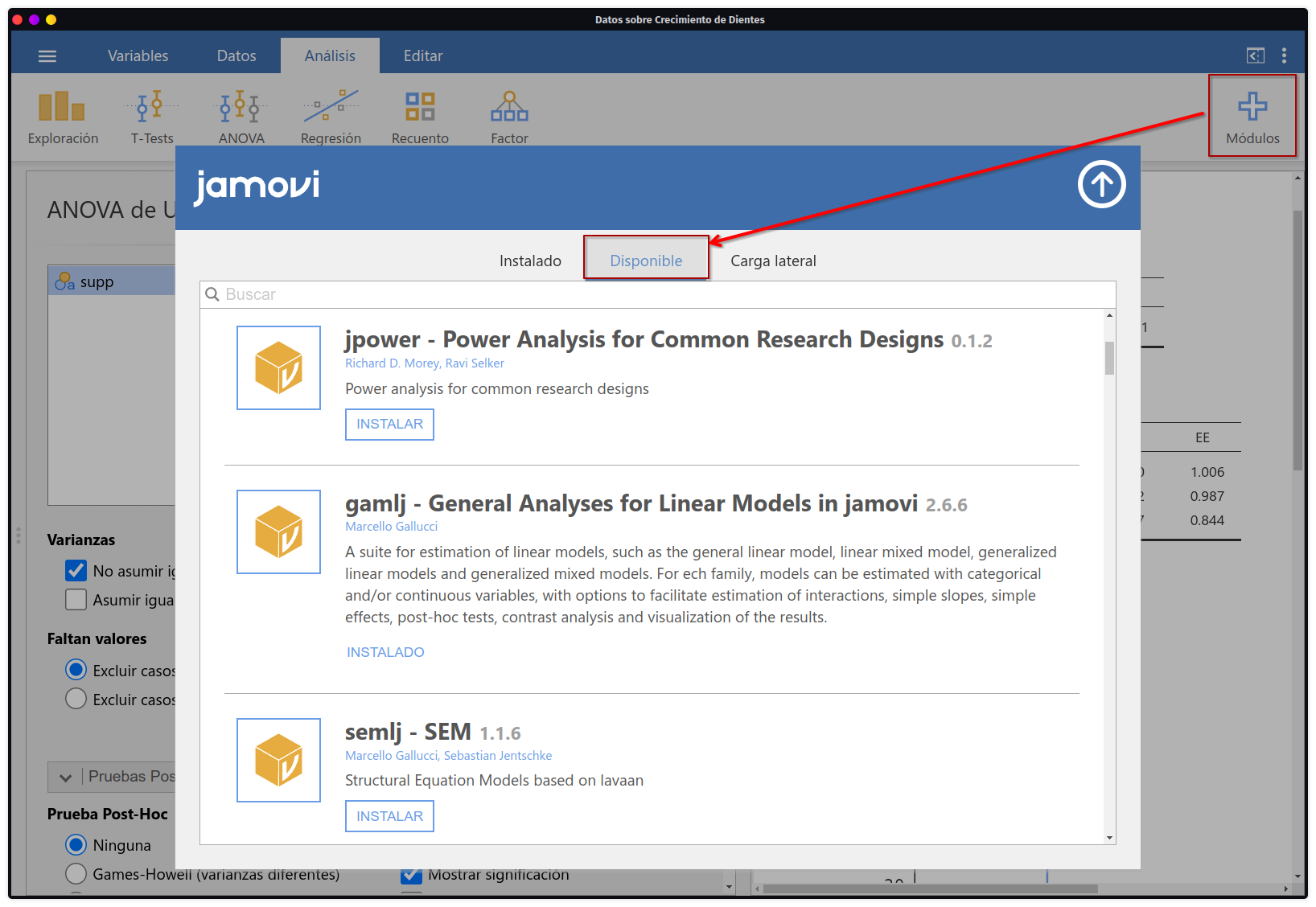
- Integración con R
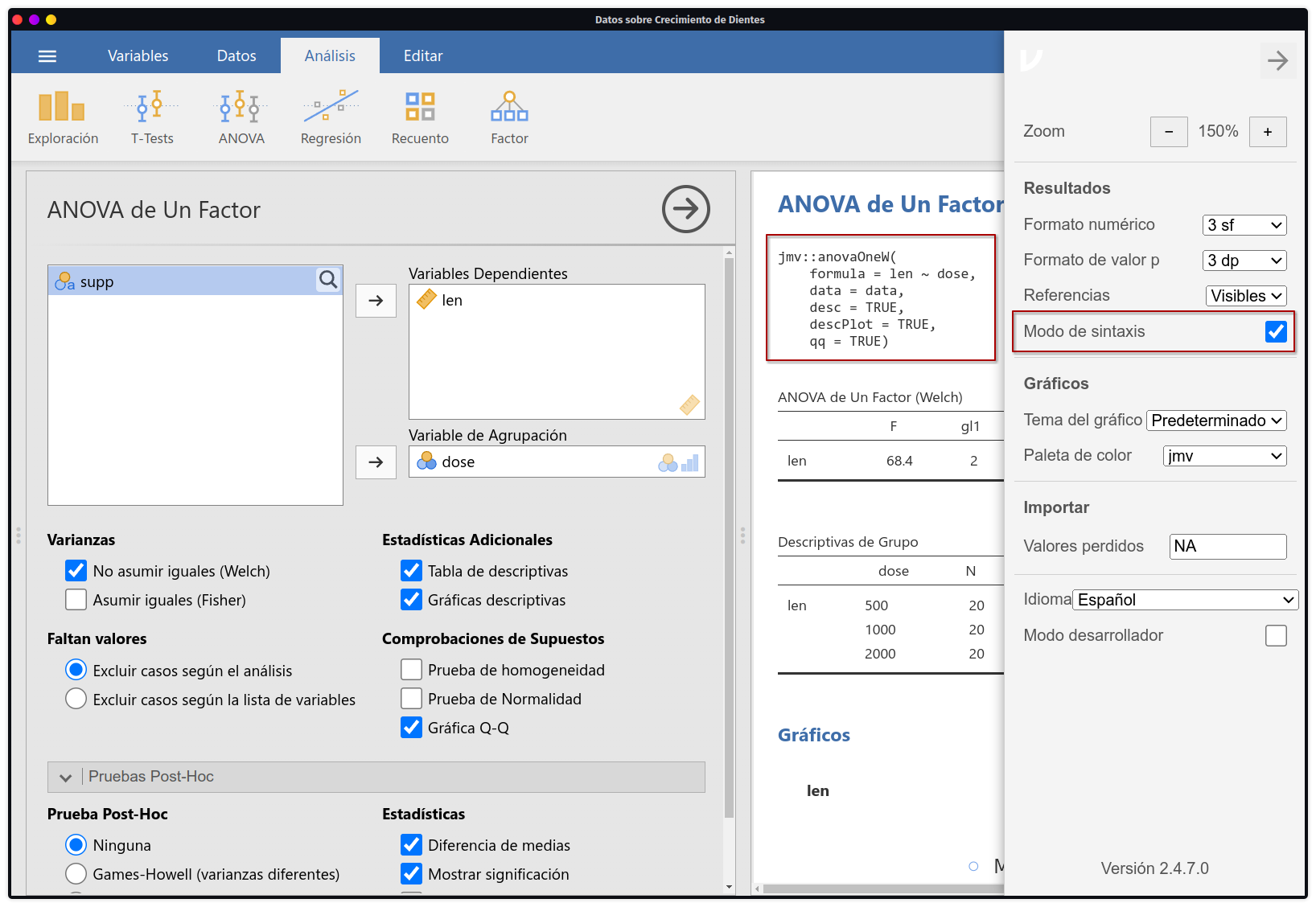
Ya que Jamovi usa a R como backend para todos sus procesos de análisis, los desarrolladores han puesto a disposición del público general 2 paquetes principales para que si el usuario desea, pueda replicar exactamente los mismos análisis que está viendo en su interfaz, pero dentro de una sesión de R. Para ello habría que instalar los siguientes paquetes:
install.packages(c('jmvcore', 'jmv'))Y dentro del software activar el modo sintaxis para que así se pueda mostrar el código R usado en cualquier análisis hecho dentro del software.
2.3.2 Ejemplificación
A fin de mantener una uniformidad en los ejemplo de los análisis, seguiremos los mismos procesos de desarrollo que los seguidos para R Commander.
2.3.2.1 Prueba t de student
- Para la parte de imporación seguiremos lo señalado en la Figura 2.21, esta vez examinando y seleccionando al conjunto de datos
lead.
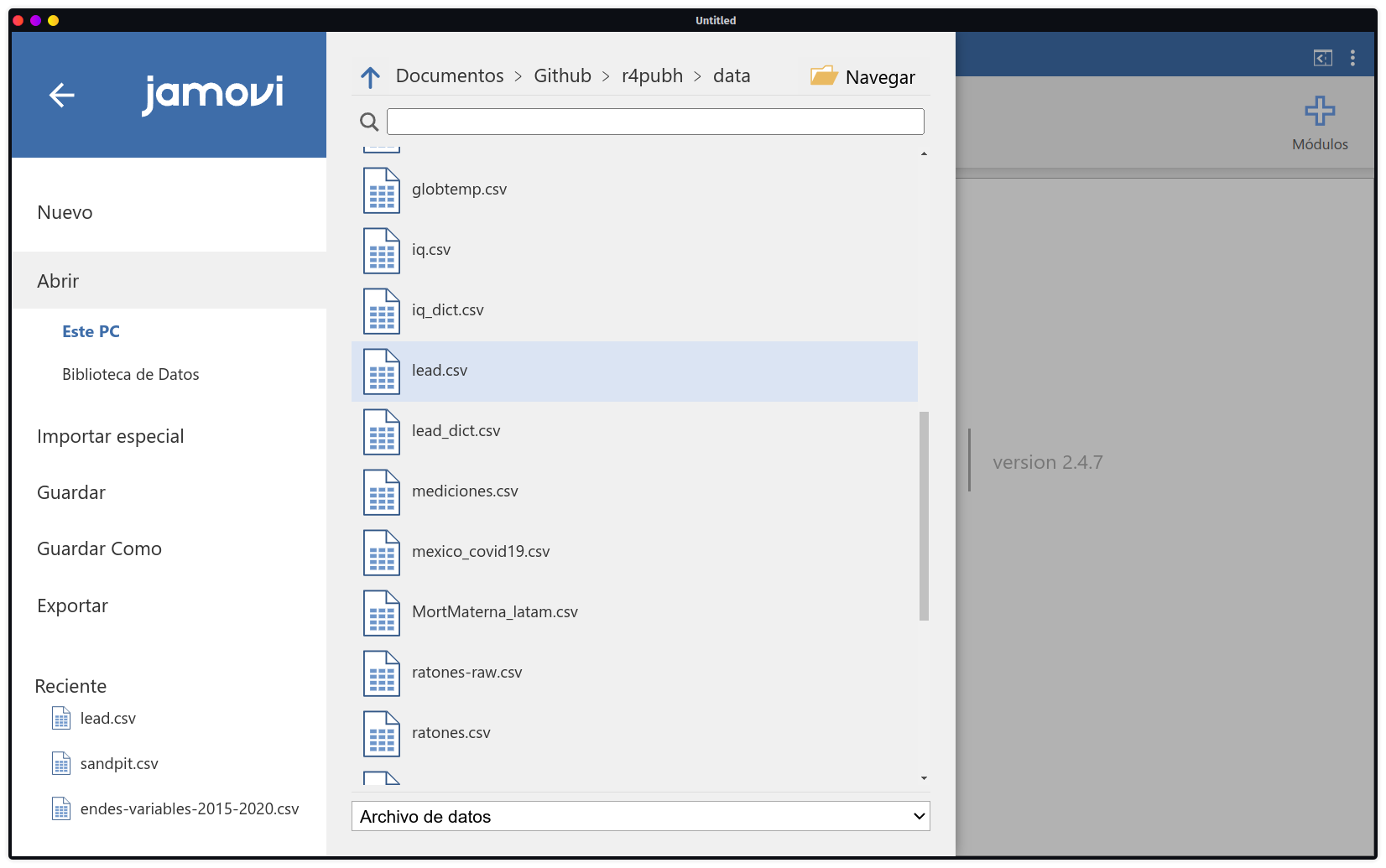
lead.csv para Jamovi
- Aunque en Jamovi no es necesario o estricto que se configure una variable como
factor, es una buena práctica asignarle etiquetas a las categorías. Para ello podemos darle doble-click en el nombre de la variableGroupy se aperturará en la parte superior un espacio de configuración para renombrar la variable, añadir alguna descripción o renombrar la categorías de las variables. En nuestro caso pondremos a1comoControly2comoExpuesto.
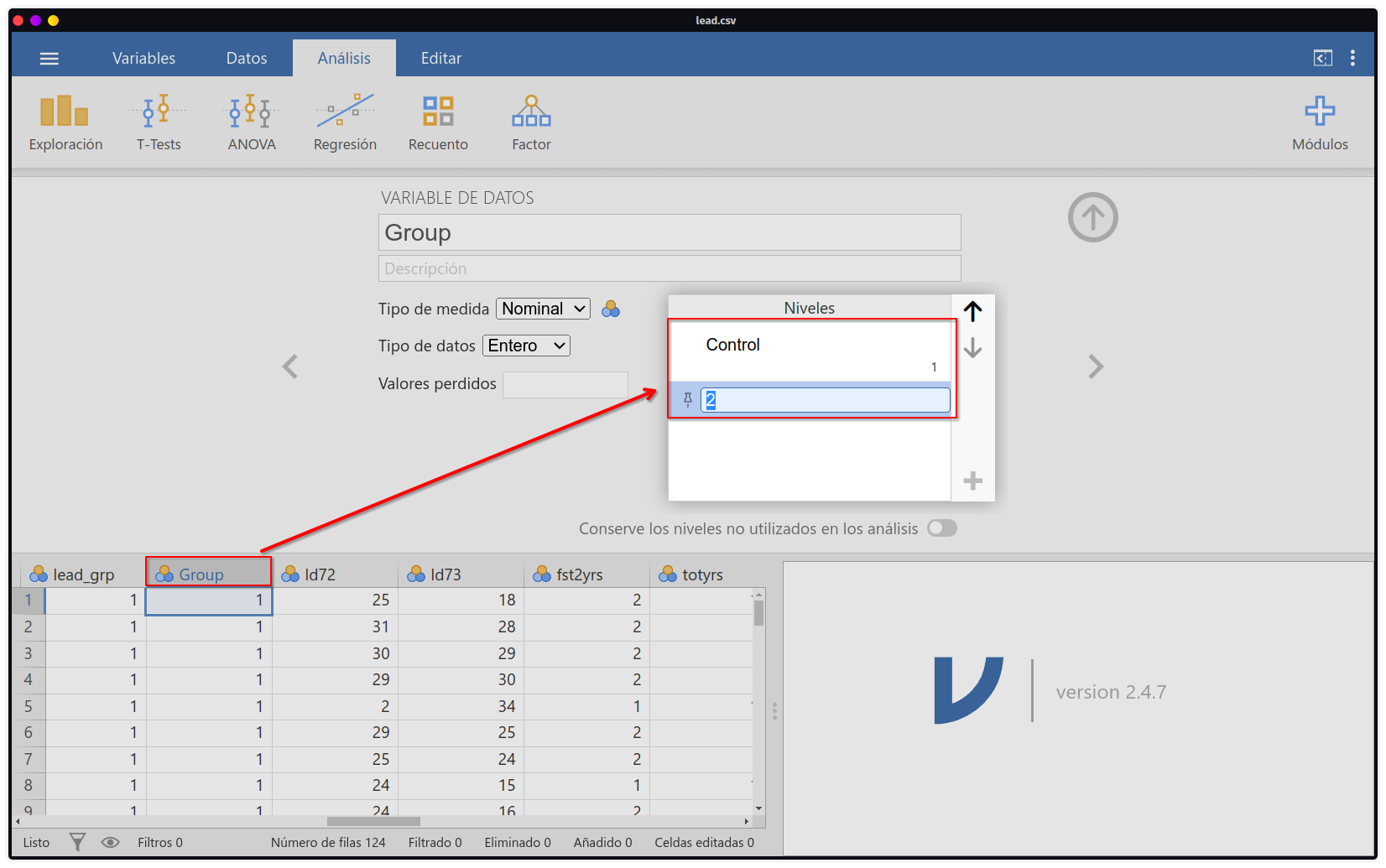
Group
- Para la selección de la prueba t-student se sigue la ruta
T-Tests > Prueba T para Muestras Independientesque se encuentra en la sección de módulos de análisis.
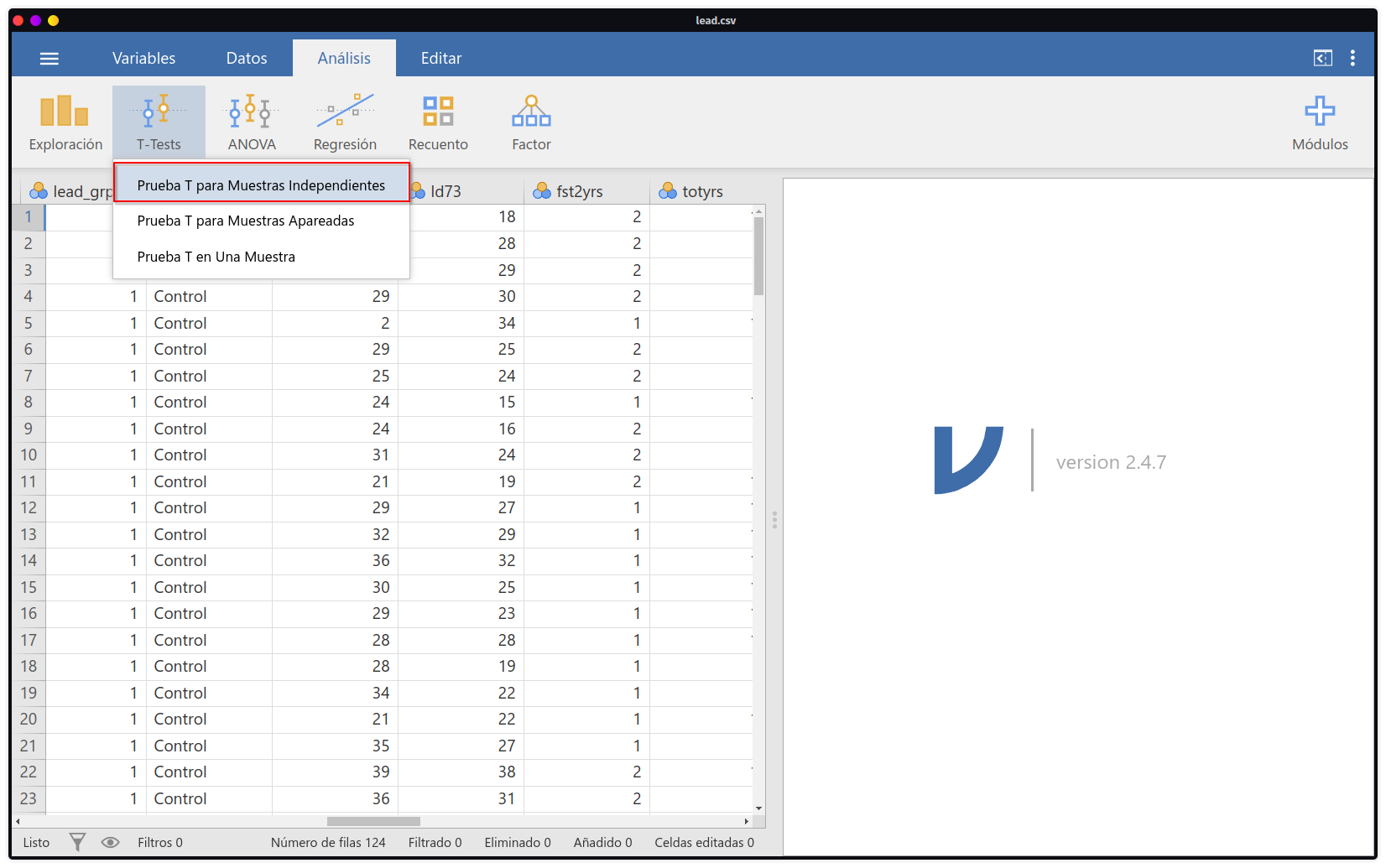
- En la ventana que se apertura se ingresa las variables dependientes, que vendrían a ser las variables contínuas con las que se ejecutará la prueba de comparación, y en la parte de
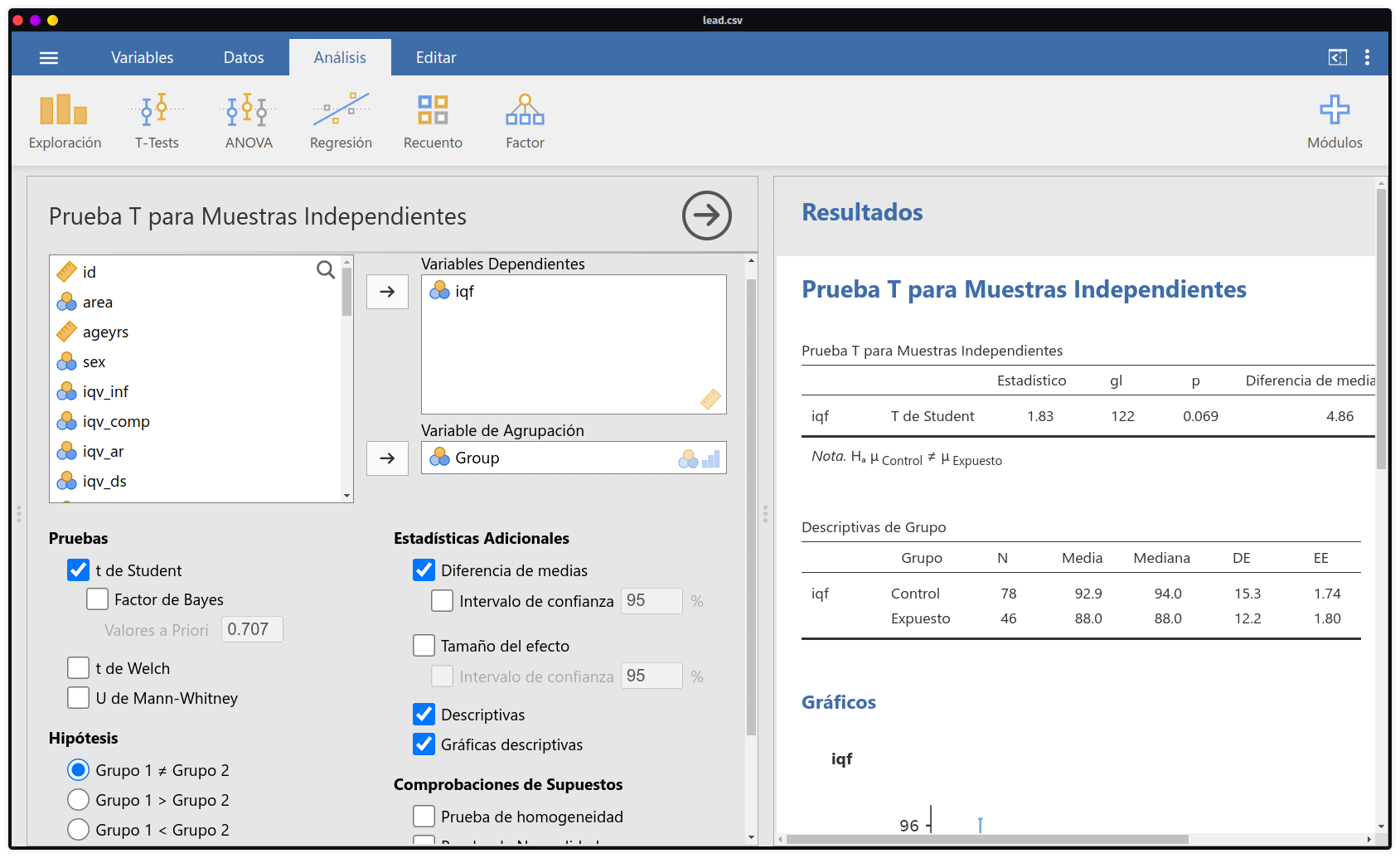
Variable de Agrupaciónse ingresará la variable que hemos codificado previamenteGroup. En esta misma ventana encontraremos diversas opciones de análisis concernientes a la prueba t, como su versión de Welch (varianza desiguales), o no parámetrica (U de Mann-Whitney), así como medidas descriptivas hasta gráficas. De igual manera que con el análisis de R Commander, se obtiene como resultado que no existen diferencias estadísticamente significativas.
2.3.2.2 Análisis de Regresión
De similar manera, en el análisis de regresión seguiremos la misma lógica que lo realizado en R Commander para este mismo análisis.
- Para el desarrollo de ello, entraremos al módulo de
Regresióny seleccionamos la opción deRegresión Lineal.
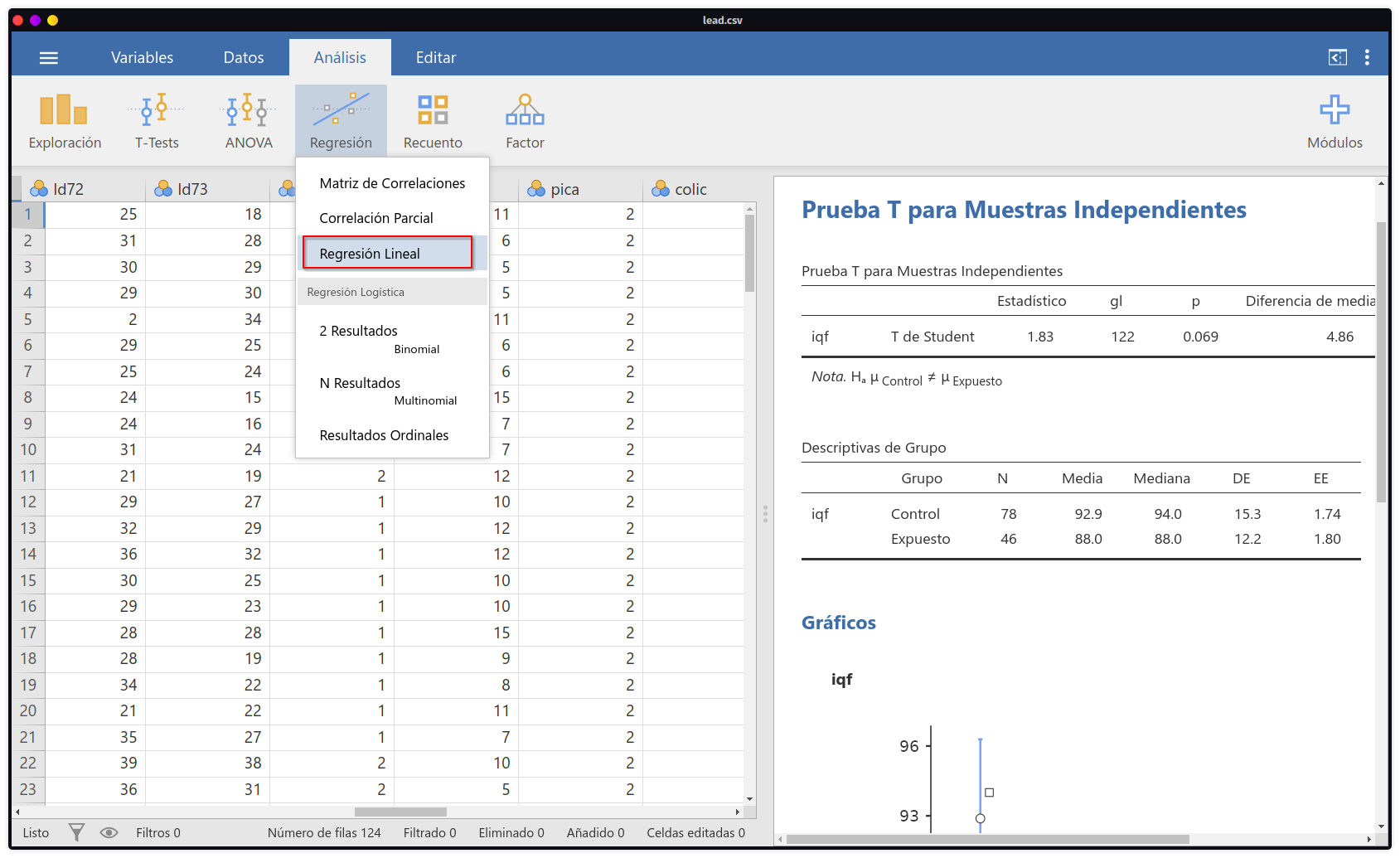
- Una vez en el módulo de análisis, habrán 4 campos con los cuales se podrá interactuar en cuánto al ingreso de variables:
- Variable dependiente: Aquí ingresaremos a
iqf - Covariables: Que serán las variables explicativas que sean contínuas/numéricas.
- Factores: Que serán las variables explicativas que sean categóricas.
- Pesos (opcional): Que se usará en caso tuvieramos un conjunto de datos con pesos muestrales.
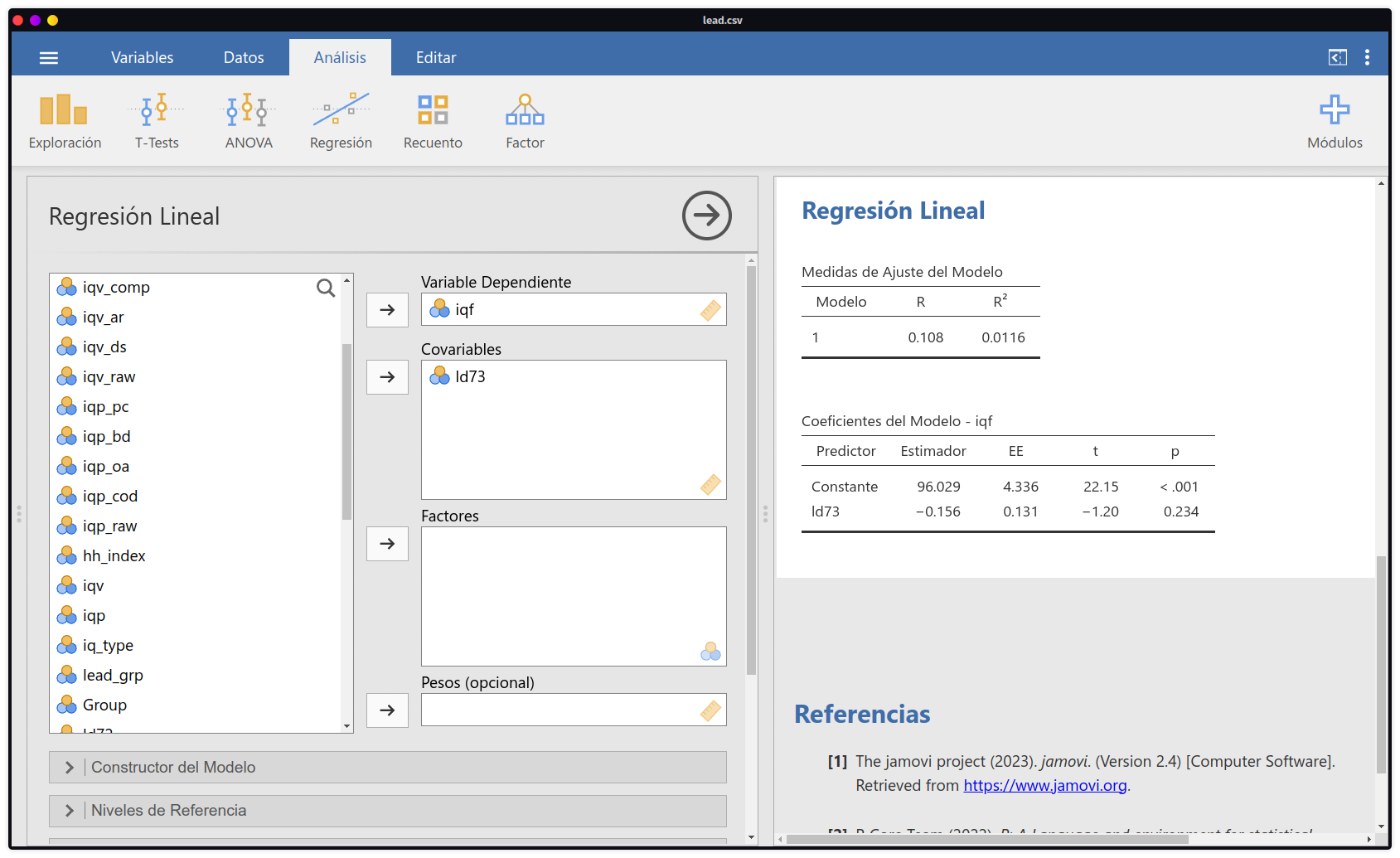
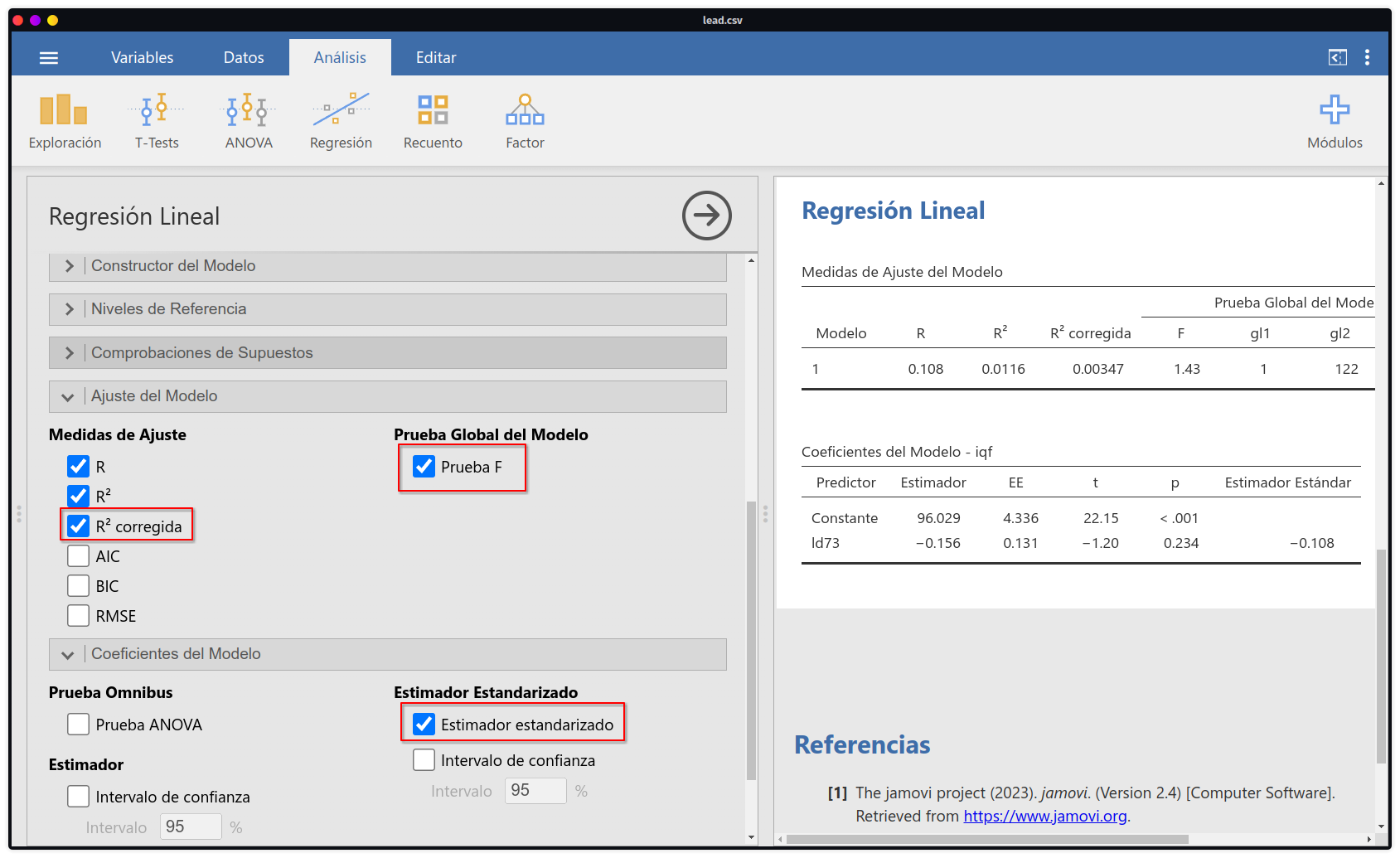
- Adicionalmente, en esta misma ventana se podrá solicitar análisis de comprobación de supuestos, más ajustes del modelo como la prueba general (overall), detalles en coeficientes del modelo como los estimadores estandarizados, entre otros. El resultado observado es el mismo que el conseguido en R Commander: el modelo de regresión de
iqfexplicado porld73no es estadísticamente significativo.
2.3.2.3 Visualización
La mayor cantidad de gráficas en Jamovi se encuentra dentro del módulo de Exploración y en la opción de Descriptivos. Sin embargo, el caso del diagrama de dispersión es particular. Si se tiene la última versión de Jamovi instalado, el módulo scatr ya viene instalado por defecto (y se podra ver dentro de Exploración). En caso no sea así, puede instalarse desde la tienda de módulo.
- En primera instancia iremos a la tienda de módulos como lo muestra la Figura 2.23. Dentro escribiremos
scatrpara encontrar el módulo que requerimos. Si indicainstaladoya no habrá que hacer nada, si indicainstalarse tendrá que hacer click y esperar a que cargue.
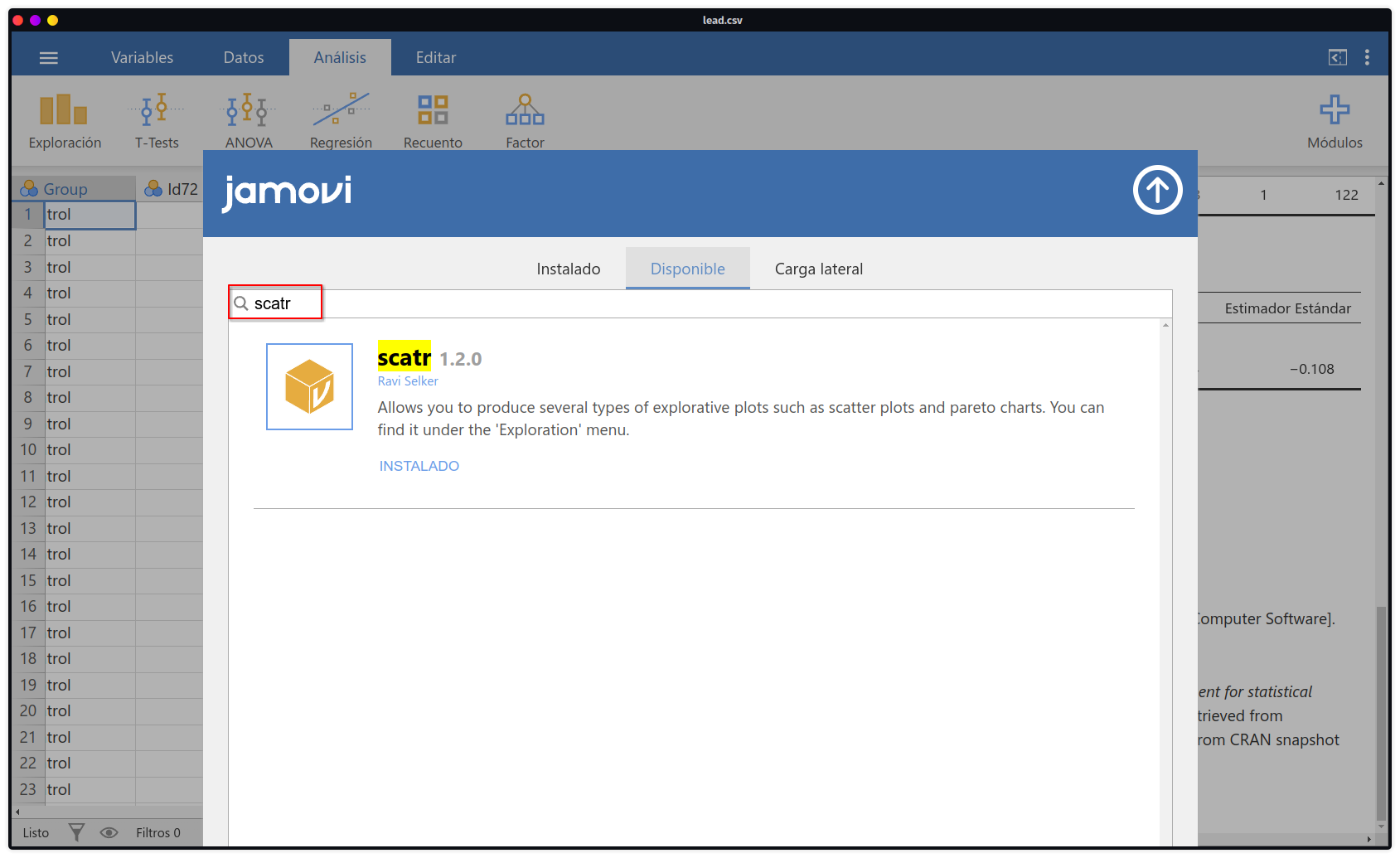
scatr en la tienda de módulos
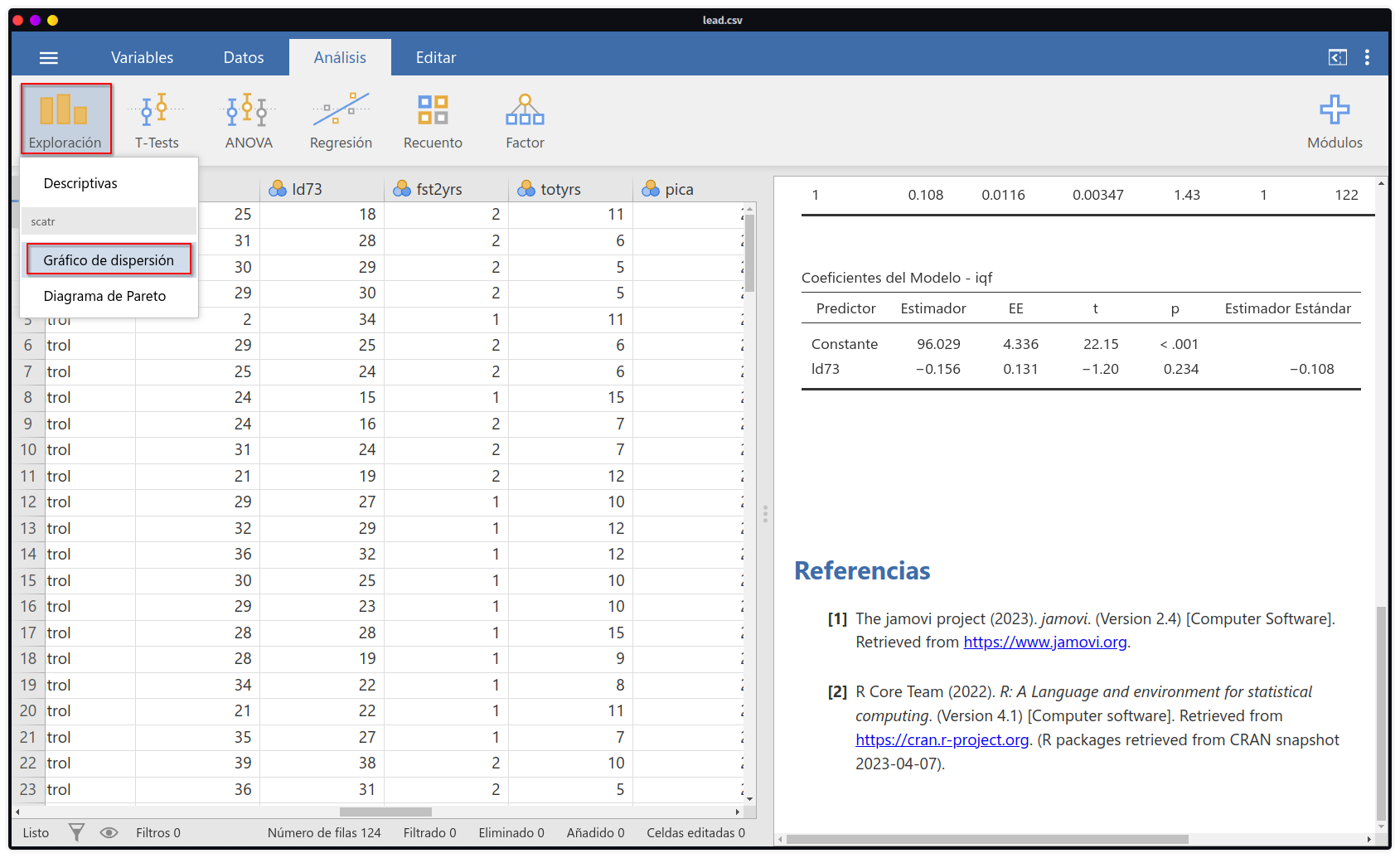
- Una vez instalado o verificado que está instalado, podremos acceder al mismo mediante la ruta:
Exploración > Gráfico de Dispersión
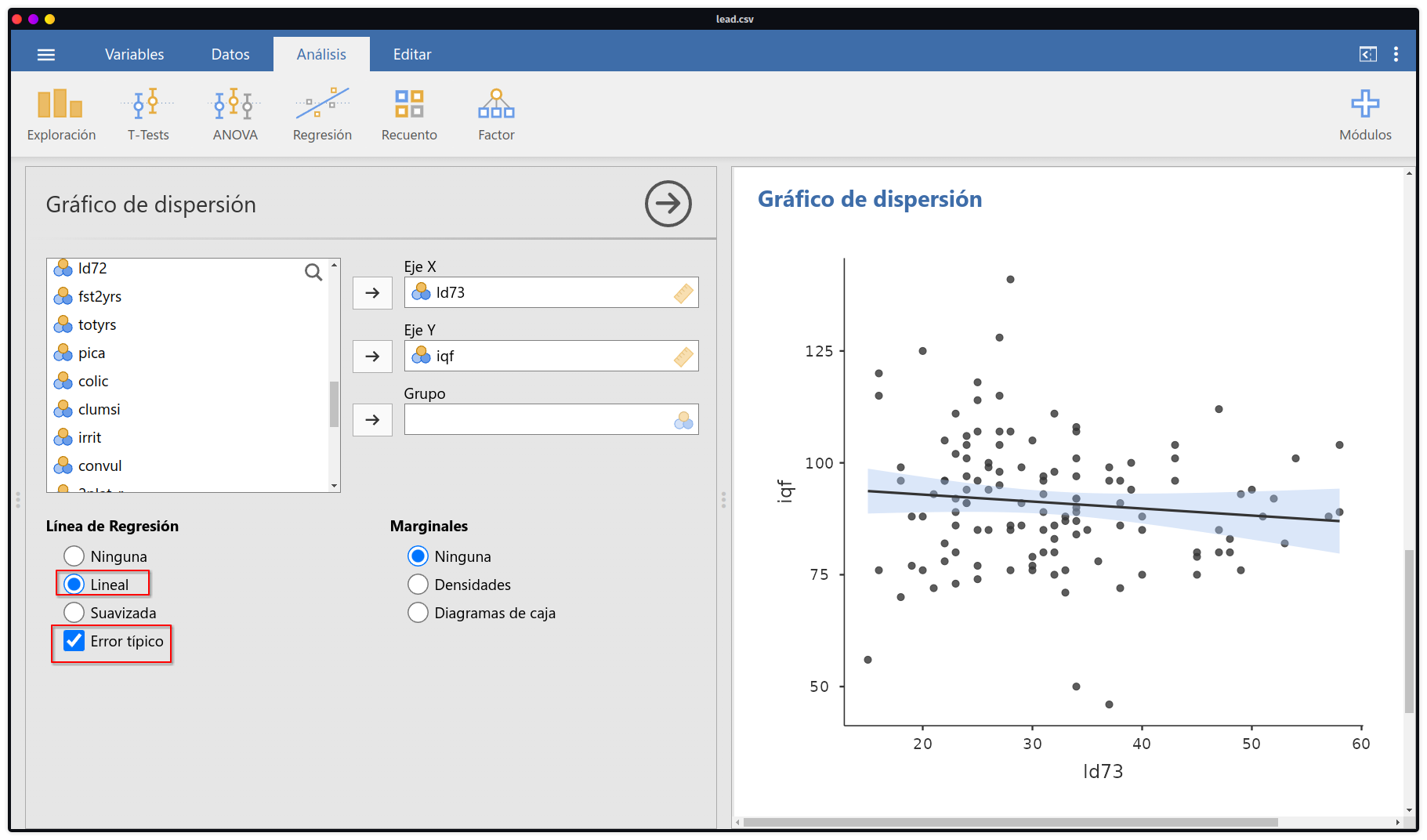
- Por último, una vez ahí se indica en el eje
xa la variableiqfy en el ejeya la variableld73, además de tener la posibilidad también de agregar la línea de ajuste de regresión y el error típico asociado.
Nota
Para una revisión más extensa sobre el uso de Jamovi se recomienda el libro de Danielle Navarro (2022) llamado “Learning statistics with jamovi”

2.4 ¿Por qué elegir R/Rstudio?
Así como R Commander y Jamovi hay otras GUI’s y formas de utilizar R sin necesidad de ir propiamente a la codificación, y en general estas alternativas con GUI’s tienen desarrollos específicos bastante bien desarrollados como ya lo hemos estado viendo en las características y ejemplificaciones de cada uno. Entonces, ¿por qué elegir R o Rstudio? A continuación, proporcionamos algunas razones:
Manejo de múltiples bases de datos en una única instancia o sesión del software: Aunque R Commander si permite importar múltiples bases de datos en su instancia, su funcionalidad para poder interactuar entre ellos es bastante limitada; mientras que en Jamovi, cada base de datos se carga en una instancia distinta. Procedimientos comunes y esenciales dentro de un análisis de datos como unificar datos a partir de variables en común, o el uso de múltiples objetos con propósitos específicos solo será posible desde R/Rstudio.
Restricción a las opciones de análisis disponibles: Si bien es cierto, muchas alternativas GUI’s proporcionan una gran variedad de análisis, el usuario estará limitado a solo y únicamente usar los análisis que el desarrollador haya incluído en la interfaz y con las opciones de configuración que se encuentren ahí. Por otro lado, con R/Rstudio y considerando únicamente al repositorio oficial CRAN, el usuario tiene acceso a más de 19800 paquetes de análisis, manejo de datos, resúmenes, automatizaciones, visualizaciones, y muchos otros procedimientos en una gran diversidad de áreas académicas y científicas. Además, de poder usar paquetes de desarrolladores independientes que puedan estar alojados en Github u otros repositorios. Las limitantes de análisis desde este punto, se reducen significativamente.
Acceso y uso directo al código fuente de las funciones: Aunque en R Commander y Jamovi, también es posible acceder a los códigos fuentes de sus análisis programados, para su entendimiento y uso el analista de todas maneras debería manejar el lenguaje R. El acceso a los códigos fuentes permite investigar, modificar y/o adaptar los análisis de interés a las necesidades propias o simplemente entender y aprender por ejercicio académico el funcionamiento de algún análisis particular de interés.
El aprendizaje directo de R/Rstudio permitirá que el usuario tenga una mayor posibilidad del entendimiento de sus datos y análisis a realizar, así como estar en contacto con una gran comunidad de usuarios que puedan estar realizando sus análisis en la misma línea de investigación. A lo largo de los capítulos de este libro mostraremos el funcionamiento básico y esencial del software R enfocado en el manejo de datos, visualización y análisis para investigación.