install.packages(c('rmarkdown', 'knitr'))Reproducibilidad con R Markdown
R Markdown es un tipo de archivo en lenguaje de marcas o markup language para el desarrollo de documentos estáticos y dinámicos basados en código en R. Si bien fue desarrollado inicialmente en este lenguaje, hoy se puede incluir código fuente de otros lenguajes como Python. En los documentos de R Markdown se puede insertar y ejecutar líneas de código, dar formato a los resultados de estos, y agregar párrafos descriptivos, imágenes, tablas, etc. Estos documentos son totalmente reproducibles y soportan varios formatos de salida como PDF, archivo de Word, HTML, entre otros.
Los documentos de R Markdown fueron diseñados para los siguientes casos de uso:
Comunicar los resultados a tomadores de decisiones, quienes quieren enfocarse en las conclusiones más que en el código.
Colaborar con otros científicos de datos, quienes están interesados tanto en conclusiones como en el código utilizado para conseguirlas.
Como un entorno donde se hace análisis de datos, como una libreta de notas donde se captura no solo lo que se hace, sino también lo que se puede estar pensando o planeando.
Existen extensiones de R Markdown que permiten generar documentos con estructura más compleja. Por ejemplo, el paquete bookdown (Xie 2016) permite generar libros con diferentes partes y capítulos. El presente libro fue desarrollado enteramente usando bookdown. Por otro lado, el paquete xaringan (Xie 2022) permite desarrollar slides para presentaciones. Para ver la lista completa de formatos de salida podemos consultar la segunda parte de Output Formats del libro R Markdown: The Definitive Guide (Xie, Allaire, y Grolemund 2018).
Requisitos
Para trabajar con R Markdown, no es necesario pero sí sumamente recomendado tener ya instalado RStudio (y R, por supuesto). RStudio ya viene con Pandoc, el cual es el motor para convertir documentos con lenguaje de marcas a diferentes formatos de salida. Una vez instalado RStudio, es necesario instalar los paquetes rmarkdown (Allaire et al. 2022) y knitr (Xie 2015). RStudio va a instalar estos paquetes cuando queramos crear un documento de R Markdown, pero si queremos hacerlo manualmente podemos ejecutar:
En el caso de que se requiera generar un documento PDF, es necesario también tener instalado una distribución de LaTex (https://www.latex-project.org/). Para los usuarios no experimentados con LaTeX, se recomienda instalar TinyTex (https://yihui.name/tinytex/), una distribución ligera de LaTeX:
install.packages('tinytex')
# Para instalar la distribución:
tinytex::install_tinytex()El paquete tinytex (Xie 2019), con la función install_tinytex(), permite instalar la distribución de LaTeX y configurar automáticamente lo necesario para que no hayan problemas a la hora de compilar documentos a PDF.
Con estos paquetes es posible generar documentos en la mayoría de formatos de salida. Sin embargo, existen extensiones que requieren otros paquetes, como los dashboards. Para una guía completa de los formatos de salida y sus requerimientos, revisar R Markdown: The Definitive Guide (Xie, Allaire, y Grolemund 2018).
Archivos de R Markdown
Los archivos de R Markdown (Rmd) tienen extensión .Rmd. A continuación, se presenta un archivo Rmd de ejemplo:
---
title: "Hello R Markdown World"
author: "Awesome Me"
date: "2022-10-07"
output: html_document
---
```{r setup, include=FALSE}
library(ggplot2)
```
## Using R Markdown
### Text
Text can be decorated with **bold** or *italics*. It is also possible to
* create [links](http://rmarkdown.rstudio.com/)
* include mathematics like $e=mc^2$ or
$$y = \beta_0 + \beta_1 x_1 + \beta_2 x_2$$
Be sure to put a space after the * when you are creating bullets and a space after # when
creating section headers, but **not** between $ and the mathematical formulas.
### Graphics
If the code of an R chunk produces a plot, this plot can be displayed in the resulting file.
```{r my-plot, fig.height=3, fig.width=5, fig.align='center'}
ggplot(data = cars, aes(speed, dist)) +
geom_point()
```
### R output
Other forms of R output are also displayed as they are produced.
```{r}
model_fit <- lm(dist ~ speed, data = cars)
summary(model_fit)
```
We can also run some line of code inline and the knitted document would print the output.
```{r}
b <- coef(model_fit)
```
For example, the slope of the regression line is `r b[2]`.
### Destination formats
This file can be knit to HTML, PDF, or Word. In R Studio, just select the desired output file type
and click on `Knit HTML`, `Knit PDF`, or `Knit Word`. Use the dropdown menu next to that to
change the desired file type.Por lo general, los archivos Rmd tienen los siguientes tres tipos de contenido importantes:
- Una cabecera YAML (opcional) rodeada por los
---. YAML (https://en.wikipedia.org/wiki/YAML) es un formato de serialización de datos que es usado en R Markdown para configurar el aspecto, formato de salida y metadata del documento, como el título, los autores, la fecha, el formato de salida, entre otros. - Bloques de líneas de código de R, también llamados chunks, que empiezan con
```{r}y terminan con```. Además, código en línea con el texto que empieza con`ry termina con`. - Texto simple y texto con formato como negrita (
**negrita**), cursiva (*cursiva*) ytexto plano(`texto plano`).
Al compilar el reporte del ejemplo, obtendremos un documento como el que se muestra en la siguiente figura:
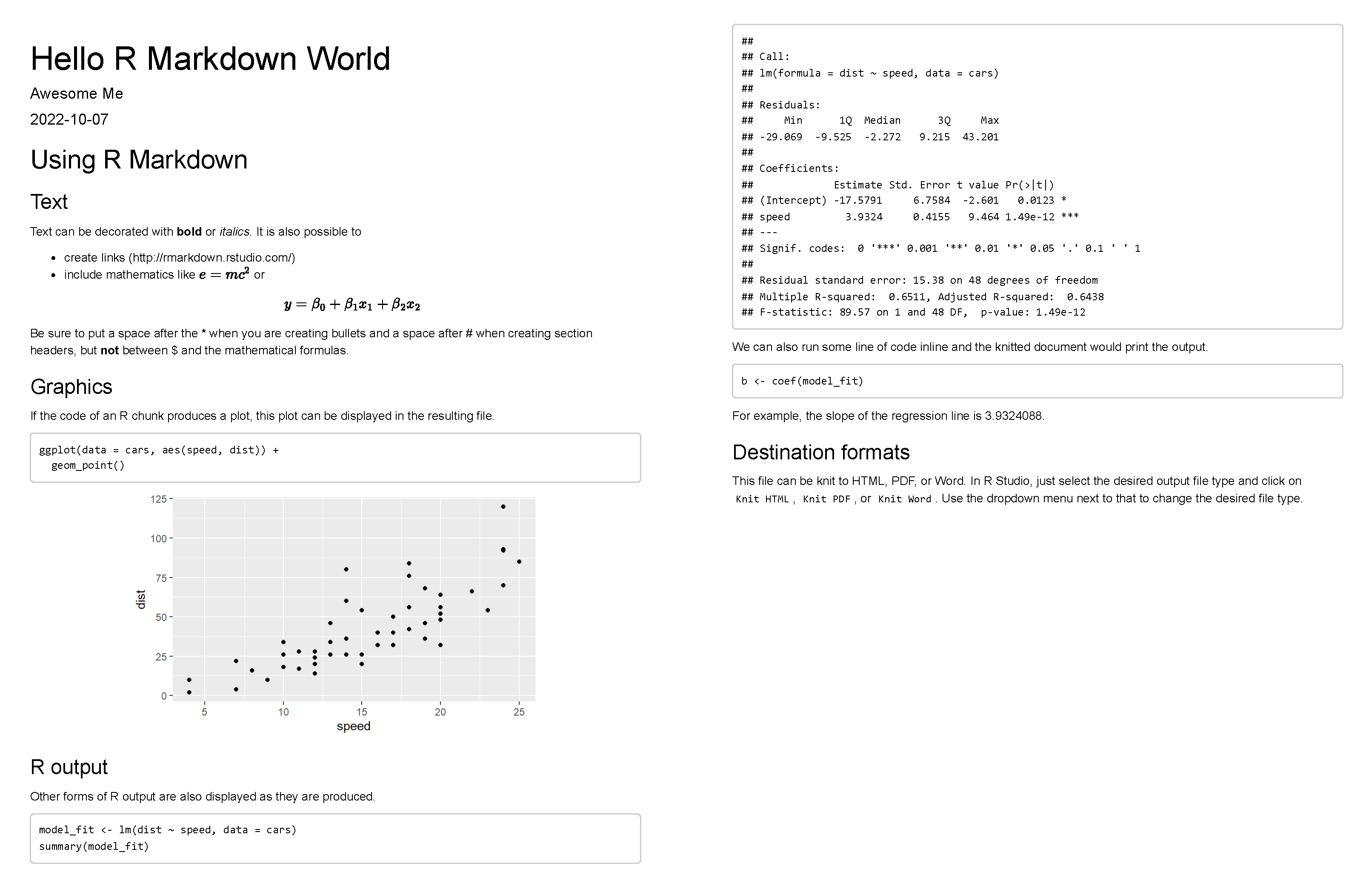
En este reporte se muestran los chunks o bloques de código, pero es posible también esconderlos para generar un reporte dirigido a un público menos técnico. En proyectos donde se utilizan datos intensivamente, R Markdown hace que la tarea de actualizar resultados, tablas o gráficos sea sumamente fácil, ya que en la mayoría de los casos solo hay que cambiar el archivo de entrada para que a la hora de compilar el documento, R Markdown ejecute los códigos e imprima los nuevos resultados en el reporte.
Compilar un archivo de R Markdown
Para generar un reporte a partir de un archivo Rmd hay que dar click al botón Knit del panel de edición. También podemos el shortcut Cmd/Ctrl+Shift+K. Otra forma es usar la función rmarkdown::render(), pasándole como primer argumento la ruta del archivo a compilar. Esto producirá el reporte en el panel de visualización o en otra ventana, y se creará un archivo con el formato de salida especificado en el directorio donde se encuentra el archivo de R Markdown.
Cuando uno le da Knit al archivo Rmd, el paquete knitr se encarga de ejecutar el código y pasar todo a un documento de lenguaje de marcas puro con al extensión .md. Luego, este archivo es convertido por Pandoc al formato de salida especificado.
Por defecto, a la hora de compilar el documento Rmd, el código se ejecutará en una nueva sesión de R. Es decir, se creará una sesión temporal aislada de la sesión de desarrollo donde se ejecutará el código del documento. Si mientras uno va desarrollando el documento Rmd va también probando el código y creando objetos, estos no estarán disponibles en la nueva sesión que se cree a la hora de compilar el documento. Por lo tanto, cualquier error que salga a la hora de compilar no estará relacionado con los objetos ya creados en la sesión de desarrollo.
Edición de formato de texto
La edición de formato de textos en archivos Rmd se hace usando la sintaxis de Markdown (https://www.markdownguide.org/), el cual es un lenguaje de marcas que consiste en una serie de convenciones de sintaxis para aplicar formato a documentos.
A continuación, veremos cómo dar formato a algunos de los elementos de texto más importantes. RStudio también cuenta con una guía básica de Markdown que se puede obtener con Help > Markdown Quick Reference.
Cabeceras
Las cabeceras o títulos de secciones pueden crearse usando secuencias del símbolo numeral (#). El número de # representa el nivel de la sección. Por ejemplo:
# Primer nivel
## Segundo nivel
### Tercer nivelPor defecto, las cabeceras se enumerarán en el documento compilado. Si se quiere que una cabecera no se enumere, hay que agregar {-} o {.unnumbered} luego de la cabecera:
# Prólogo {-}Énfasis
Se puede dar énfasis al texto con las siguientes sintaxis:
-
cursiva:
*cursiva*o_cursiva_ -
negrita:
**negrita**o__negrita__ -
texto plano:`texto plano`
Hipervínculos
Para incluir hipervínculos, usar la siguiente sintaxis: [etiqueta](link). Por ejemplo [R Markdown](https://rmarkdown.rstudio.com/) produce R Markdown.
Listas
Para crear listas ordenadas:
1. Primer ítem
2. Segundo ítem
3. Tercer ítemEsto produce la siguiente lista:
- Primer ítem
- Segundo ítem
- Tercer ítem
Para crear una lista no numerada, se pueden usar los símbolos *, -, o +:
- Ítem
- Ítem
- ÍtemEl resultado es:
- Ítem
- Ítem
- Ítem
Se puede hacer listas con niveles agregando sangrías (dos TAB). Además, es posible combinar lista ordenadas y no numeradas:
1. Primer ítem
- Sub-ítem
- Sub-ítem
2. Segundo ítem
- Sub-ítem
- Sub-ítemEl resultado es el siguiente:
- Primer ítem
- Sub-ítem
- Sub-ítem
- Segundo ítem
- Sub-ítem
- Sub-ítem
Expresiones matemáticas
Se puede añadir expresiones matemáticas al documento usando la sintaxis de LaTeX. Para expresiones en línea con el texto, tenemos que rodearlas con un símbolo de dólar ($). Por ejemplo $f(k) = {n \choose k} p^{k} (1-p)^{n-k}$ produce \(f(k) = {n \choose k} p^{k} (1-p)^{n-k}\). Para insertar expresiones en modo de exhibición (en su propia línea), hay que rodearlas con dos símbolos de dólar ($$). Por ejemplo, $$f(k) = {n \choose k} p^{k} (1-p)^{n-k}$$ produce: \[f(k) = {n \choose k} p^{k} (1-p)^{n-k}\]
También es posible añadir estructuras matemáticas más complejas dentro de $ o $$. Por ejemplo, para añadir una matriz de 4x4:
$$\begin{array}{ccc}
x_{11} & x_{12} & x_{13}\\
x_{21} & x_{22} & x_{23}
\end{array}$$\[\begin{array}{ccc} x_{11} & x_{12} & x_{13}\\ x_{21} & x_{22} & x_{23} \end{array}\]
Se recomienda revisar el wikibook LaTeX/Mathematics como referencia para la sintaxis de LaTeX para expresiones matemáticas.
Chunks
Los chunks o bloques de código son la característica principal de los documentos de R Markdown. Permiten insertar y ejecutar código en el mismo documento. Para insertar un chunk podemos
- Usar el shortcut
Cmd/Crtl+Alt+I, - Dar click en ‘Insert a new code chunk’ en el panel de edición.
- Escribir manualmente los delimitadores
```{r}y```.
Para ejecutar un chunk, damos click en el botón Run en la parte superior del editor o usamos el shortcut Cmd/Ctrl+Shift+Enter. RStudio ejecuta el código y muestra los resultados en línea. Al igual que en un script de R, para correr una línea de código dentro del chunk se usa Cmd/Ctrl + Enter.
Nombramiento
Los chunks pueden nombrarse usando la sintaxis ```{r nombre}. Nombrar a los chunks tiene las siguientes ventajas:
- Podemos navegar fácilmente a un chunk específico usando el navegador de código en la parte inferior izquierda del editor.
- Los gráficos que produzcan los chunks van a tener nombres únicos que luego se pueden utilizar en otra parte del documento.
- Se puede configurar una serie de chunks para que estén almacenados en caché para prevenir volver a correr procesos computacionalmente costosos.
Existe un nombre de chunk que produce un comportamiento especial: setup. A la hora de compilar el docuemtno, el chunk llamado setup se correrá solo una vez, antes de cualquier otro chunk.
Opciones locales
Los chunks tienen opciones locales que permiten configurar el comportamiento de cada chunk. Estas opciones se incluyen como argumentos dentro de las cabeceras ```{r} de cada chunk. Hay casi 60 opciones que se pueden usar, y aquí mencionaremos solo las más importantes. Para ver la lista completa, se puede recurrir a http://yihui.name/knitr/options/.
Las opciones más importantes controlan si un chunk es ejecutado o no y qué resultados son incluidos en el reporte compilado:
-
echo=FALSE: Muestra el resultado pero no el código. -
eval=FALSE: Previene que un bloque de código sea ejecutado. Eso es útil para mostrar código de muestra o para deshabilitar un bloque de código sin tener que comentar cada línea. -
include=FALSE: Ejecuta el código, pero no muestra el código o resultado en el documento final. Esto es útil para el chunk de setup. -
message=FALSEowarning=FALSE: Previene que mensajes o advertencias se impriman en el reporte final, respectivamente. -
results='hide': Esconde los resultados. -
collapse=TRUE: Colapsa el código y la salida en un único bloque.
Opciones globales
Para configurar las opciones de todos los chunks en el archivo podemos llamar a knitr::opts_chunk$set() en un chunk, preferentemente el de setup. Por ejemplo, para colapsar los códigos y sus resultados cada uno en un solo bloque en todo reporte, podemos usar collapse = TRUE:
knitr::opts_chunk$set(collapse = TRUE)Si se quisiera esconder todo el código en el documento, podemos usar echo = FALSE:
knitr::opts_chunk$set(echo = FALSE)No es muy recomendable asignar message=FALSE y warning=FALSE como opciones globales, ya que esto hace más difícil depurar errores.
Código en línea con el texto
Para agregar código de R en línea con el texto podemos usar `r `. Por ejemplo, para poner cuántas observaciones tiene la base de datos mtcars, podemos tipear `r nrow(mtcars)`. Cuando se compile el documento se imprimirá el resultado: 32.
Tablas
Por defecto, R Markdown imprime data frames y matrices como se imprimirían en la consola:
mtcars %>%
filter(mpg > 20) mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2Si se quisiera mostrar las tablas con un mejor formato, podemos usar la función kable() del paquete knitr:
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Merc 240D | 24.4 | 4 | 146.7 | 62 | 3.69 | 3.190 | 20.00 | 1 | 0 | 4 | 2 |
| Merc 230 | 22.8 | 4 | 140.8 | 95 | 3.92 | 3.150 | 22.90 | 1 | 0 | 4 | 2 |
| Fiat 128 | 32.4 | 4 | 78.7 | 66 | 4.08 | 2.200 | 19.47 | 1 | 1 | 4 | 1 |
| Honda Civic | 30.4 | 4 | 75.7 | 52 | 4.93 | 1.615 | 18.52 | 1 | 1 | 4 | 2 |
| Toyota Corolla | 33.9 | 4 | 71.1 | 65 | 4.22 | 1.835 | 19.90 | 1 | 1 | 4 | 1 |
| Toyota Corona | 21.5 | 4 | 120.1 | 97 | 3.70 | 2.465 | 20.01 | 1 | 0 | 3 | 1 |
| Fiat X1-9 | 27.3 | 4 | 79.0 | 66 | 4.08 | 1.935 | 18.90 | 1 | 1 | 4 | 1 |
| Porsche 914-2 | 26.0 | 4 | 120.3 | 91 | 4.43 | 2.140 | 16.70 | 0 | 1 | 5 | 2 |
| Lotus Europa | 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.90 | 1 | 1 | 5 | 2 |
| Volvo 142E | 21.4 | 4 | 121.0 | 109 | 4.11 | 2.780 | 18.60 | 1 | 1 | 4 | 2 |
Para mayor información sobre la configuración de estas tablas, revisar la documentación de la función con ?knitr::kable.
El paquete kableExtra (Zhu 2021) es una extensión que permite un control más avanzado para el diseño de tablas. Otros paquetes con funcionalidades más avanzadas son gt (Iannone, Cheng, y Schloerke 2022), flextable (Gohel 2022) y huxtable (Hugh-Jones 2022).
Figuras
Por defecto, las figuras se mostrarán justo debajo de los chunks con las que fueron generadas. Usando las opciones locales o globales, podemos mostrar o no el código de estos chunks (echo). Otras opciones de chunk útiles para generar figuras son:
-
fig.widthyfig.height: Controlan el ancho y el alto de las figuras (en pulgadas, por defecto), respectivamente. Por ejemplo,fig.width = 8yfig.height = 9producen una figura con 8 pulgadas de ancho y 6 pulgadas de alto. Si se quiere usar otra unidad, podemos pasar la medida y la unidad entre comillas. Por ejemplo,fig.width = '8cm'yfig.height = '9cm'producen una figura de 8 cm de ancho y 6 cm de alto. -
out.widthyout.height: Controlan la relación de aspecto de la figura en el reporte compilado. Por ejemplo, para que se imprima la figura con el 50% del ancho original pero conservando la relación de aspecto ponemosout.width='50%'. -
fig.align: Controla la alineación de la figura. Puede tomar los valores'right','left'y'center'. -
fig.caption: Permite ponerle un título a la figura. Por ejemplo,fig.caption = 'Una figura'.
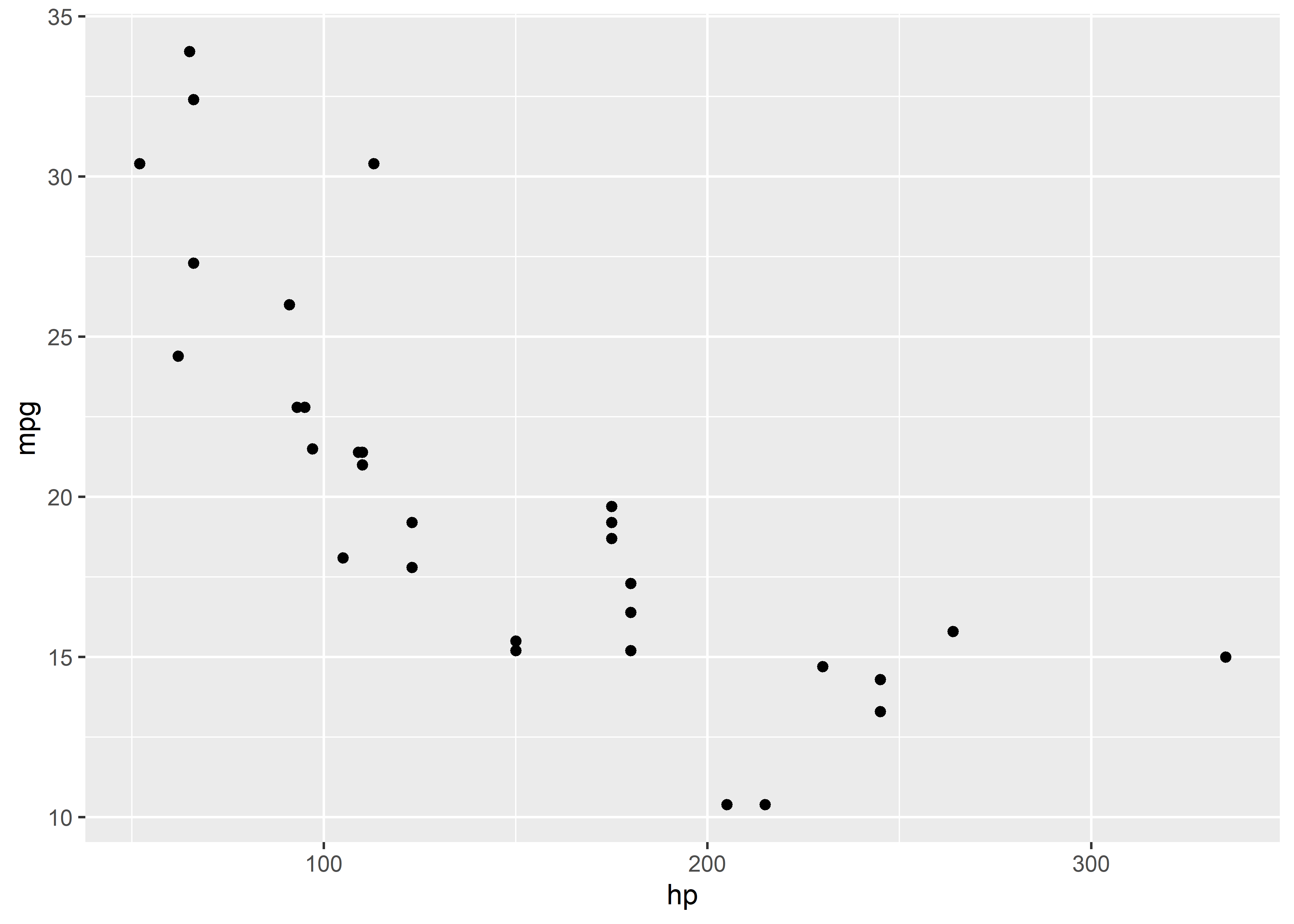
Veamos, como ejemplo, el siguiente chunk con las opciones por defecto:
```{r}
ggplot(mtcars, aes(hp, mpg)) +
geom_point()
```Al ejecutar este chunk, obtenemos la siguiente figura:
Ahora, configuremos el tamaño y la alineación, y agreguemos un título:
```{r fig.width = 4, fig.height=3, fig.align='center', fig.cap='Una figura'}
ggplot(mtcars, aes(hp, mpg)) +
geom_point()
```Al ejecutarlo obtenemos:
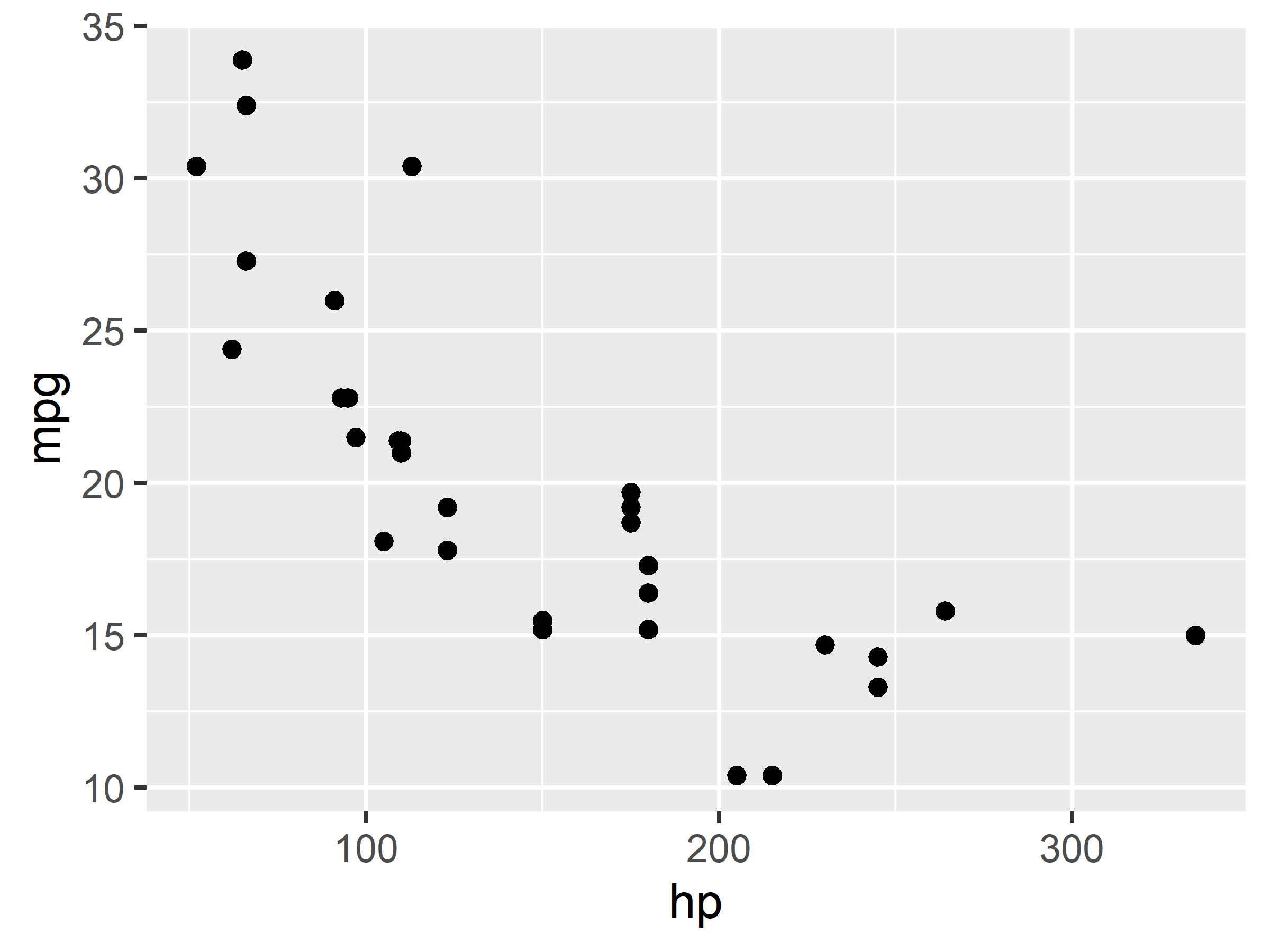
Para insertar una figura externa que no se genera en el mismo documento con código en R, podemos usar la función knitr::include_graphics(). Por ejemplo:
knitr::include_graphics('figures/cat.jpg')
Metadata y control del documento
Podemos controlar el aspecto, formato de salida y metada del documento usando una cabecera con sintaxis YAML (https://en.wikipedia.org/wiki/YAML), el cual es un formato de serialización de datos.
Al crear un documento de R Markdown con RStudio, este nos solicitará alguna metadata para el documento, como el título, el autor, la fecha y el formato de salida. También podemos elegir la opción de crear un documento vacío.
En el caso de que hayamos suministrado la metadata, RStudio creará un documento R Markdown nuevo con la siguiente cabecera en formato YAML:
---
title: "Untitled"
author: "Diego Villa"
date: "2024-05-28"
output: html_document
---En las siguiente secciones veremos opciones para cambiar o agregar metadata en el documento de R Markdown.
Título y subtítulo
Para especificar el título y subtítulo usamos title y subtitle. Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
---Autor(es)
Para especificar uno o varios autores usamos la opción author y listamos a los autores con comas:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
---Fecha
Para especificar la fecha, usar la opción date. Es posible ingresar una fecha manualmente como texto, por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "10 de octubre de 2022"
---También podemos insertar una fecha dinámica usando código de R línea que devuelva la fecha en la que se compila el documento. La función en R que permite hacer esto es Sys.date(), la cual devuelve la hora del sistema. Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "2024-05-28"
---Cabe resaltar que Sys.Date() devuelve la fecha en formato ‘%Y-%m-%d’ (Year-month-day, por ejemplo: 2022-10-10). Para cambiar el formato podemos usar la función format() sobre Sys.Date() y especificar como argumento el formato deseado. Por ejemplo, format(Sys.time(), '%d %B, %Y') devuelve la fecha en formato 10 October, 2022. En la cabecera se vería así:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
---Podemos referirnos a este blog para una guía rápida de la sintaxis para dar formato a las fechas en R.
Formato de salida
El formato de salida se puede especificar usando la opción output. Por defecto, el formato de salida es html_document, es decir, en formato HTML. Algunos otros formatos de salida son:
- PDF:
pdf_document - Word:
word_document - LaTeX:
latex_document - Markdown:
md_document
La generación de presentaciones no está incluida en este libro, pero algunos de los formatos de salida disponible son:
- PowerPoint:
powerpoint_presentation - Beamer:
beamer_presentation
De nuevo, podemos revisar R Markdown: The Definitive Guide (Xie, Allaire, y Grolemund 2018) o el libro R Markdown Cookbook (Xie, Dervieux, y Riederer 2020) para una guía completa sobre los formatos de salida de R Markdown.
Tabla de contenidos
Se puede agregar una tabla de contenidos en el reporte usando la opción toc y especificando la profundidad de los encabezados mediante toc_depth. Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
output:
html_document:
toc: true
toc_depth: 2
---Si toc_depth no se especifica, por defecto se mostrarán 3 niveles de encabezados.
Tabla de contenidos flotante
Podemos usar la opción toc_float para que la tabla de contenidos sea flotante (separada del texto) y aparezca a la izquierda. En este caso, cuando estemos navegando por el documento, la tabla de contenidos siempre va a ser visible.
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
output:
html_document:
toc: true
toc_float: true
---Opcionalmente, se puede especificar una lista de opciones para toc_float que controlen su comportamiento. Entre estas opciones están:
collapsed(TRUEpor defecto): Controla si es que la tabla de contenidos muestra solo los encabezados de nivel superior. Si se colapsa, la tabla de contenidos se expande automáticamente en línea cuando sea necesario.smooth_scroll(TRUEpor defecto): Controla si los desplazamientos de página se animan cuando se navega por los elementos de la tabla de contenidos mediante clics.
Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
output:
html_document:
toc: true
toc_float:
collapsed: false
smooth_scroll: false
---Más información
Para más información sobre R Markdown, podemos referirnos a la web https://rmarkdown.rstudio.com/ o los libros R Markdown: The Definitive Guide (Xie, Allaire, y Grolemund 2018) y R Markdown Cookbook (Xie, Dervieux, y Riederer 2020).
Ejercicios
Para estos ejercicios utilizaremos el conjunto de datos del archivo fev.csv para generar un reporte con R Markdown. Este conjunto de datos contiene parte de las observaciones del estudio realizado por Tager et al. (1979), quienes investigaron el efecto del tabaquismo de los padres en la función pulmonar de sus hijos en East Boston, Massachusetts. Este archivo de datos fue recuperado del repositorios de datos de Rosner (2015). El conjunto de datos contiene observaciones hechas a 654 niños y jóvenes de 3 a 19 años sobre la edad (age), el volumen espiratorio forzado (litros) entre 25% y 75% de la capacidad vital (fev), la altura (hgt), el sexo (sex), y si fuma habitualmente o no (smoke).
Siga las siguientes indicaciones para generar un reporte con el análisis del conjunto de datos del archivo fev.csv:
- Cree un archivo R Markdown y modifique la metadata de la cabecera YAML agregando título, nombre de autor y fecha.
- Luego de la cabecera, inserte un chunk de setup donde se llame al paquete tidyverse.
- Cree las secciones de Lectura de datos, Procesamiento de datos, y Análisis exploratorio de datos.
- En la sección de Lectura de datos, incluya el código para leer el archivo
fev.csv. - En la sección de Procesamiento de datos realice las siguientes operaciones:
- Revise las variables que contiene el conjunto de datos. (Pista: Usar
str(),summary()y/odplyr::glimpse()) - Remueva la variable
id. - Si es que fuera necesario, eliminar las observaciones vacías.
- Convierta la variable
smokeen factor y agregue las etiquetas (labels) para los niveles0:"Non-current smoker"y1:"Current smoker". - Convierta la variable
sexen factor y agregue las etiquetas para los nivles0:Femaley1:Male. - Cree una factor con grupos de edades con los siguiente niveles ordenados: de 3 a 4 años (
"3-4"), 5 a 9 años ("5-9"), 10 a 14 años ("10-14"), y 15 a 19 años ("15-19").
- Revise las variables que contiene el conjunto de datos. (Pista: Usar
- En la sección de Análisis exploratorio de datos, realizar los siguientes análisis:
- Generar una tabla cruzada entre el status de fumador (
smoke) y el sexo (sex) con los porcentajes en cada grupo. (Pista: Usarjanitor::tabyl()) - Calcule el promedio del volumen espiratorio (
fev) por grupo etario. - Calcule el promedio del volumen espiratorio en los grupos de fumadores y no fumadores.
- Generar un gráfico de cajas para el volumen espiratorio por grupo etario.
- Modificar el gráfico anterior para distinguir el color de las cajas según estatus de fumador (Pista: Usar
fill). - Modificar el gráfico anterior para generar facetas (gráficos separados) por sexo (Pista: Usar
facet_wrap).
- Generar una tabla cruzada entre el status de fumador (
- Compilar el reporte en HTML.