install.packages('knitr')8 Reproducibilidad con Quarto y Github
La reproducibilidad de un análisis trae consigo una gran cantidad de ventajas a la vez que problemas a resolver. Por ejemplo, podríamos tener todo un proyecto de análisis que pueda ser replicado por revisores, pares analistas, otros equipos de investigación, etc., mejorando la retroalimentación o calidad del trabajo de análisis que hayamos realizado. Pero para poder lograr esto, tendríamos como mínimo, asegurarnos de que todo y absolutamente todo los procedimientos asociados al análisis se encuentren registrados, tener el mismo entorno de análisis, paquetes, una forma de controlar los cambios o crear un registro de ellos, interactuar con estos cambios y que ellos también lo puedan realizar.
Resolver lo anterior es una tarea sumamente importante así como amplia y exije en algunas ocasiones cierto nivel técnico de los interesesados/analistas para poder llevarlo a cabo. En este capítulo vamos a centrarnos en 2 herramientas puntuaciones que nos permitirán resolver 2 importantes tareas:
- Quarto: Para un registro detallado, ordenado y comentado de todo el proceso de análisis que estemos siguiendo.
- Github: Para poder registrar nuestros archivos de análisis, realizar cambios, seguimientos, interactuar con los cambios de otras personas, recibir retroalimentaciones y poder regresar a una versión en específica de un cambio si lo deseamos. Por ejemplo, un análisis que se hizo inicialmente que se descartó, pero ahora se quiere recuperar.
8.1 Quarto
Quarto es un nuevo tipo de formato para analizar, compartir y reproducir información mediante un proceso de compilación a formatos html, pdf, word, e incluso para hacer diapositivas, páginas web tipo blog o creación de libros. De hecho este libro está realizado con quarto. De forma similar a Rmarkdown, se desarrolló en principio para R, pero actualmente puede usarse desde python, julia y javascript.
Este nuevo formato usa por debajo a markdown que es un tipo de en lenguaje de marcas o markup language para el desarrollo de documentos estáticos que con la ayuda de quarto puede ejecutar bloques de códigos que se encuentren presentes en el documento para poder mostrar resultados, tablas, gráficos e incluso, lograr que el documento pueda tener un comportamiento dinámico.
Los documentos de Quarto fueron diseñados para los siguientes casos de uso:
- Comunicar los resultados a tomadores de decisiones, quienes quieren enfocarse en las conclusiones más que en el código.
- Colaborar con otros científicos de datos, quienes están interesados tanto en conclusiones como en el código utilizado para conseguirlas.
- Como un entorno donde se hace análisis de datos, como una libreta de notas donde se captura no solo lo que se hace, sino también lo que se puede estar pensando o planeando.
Quarto y Rmarkdown
Aunque el posicionamiento de Rstudio (encargados del desarrollo de quarto) es que las personas no deberían dejar de usar Rmarkdown de inmediato o migrar todos sus proyectos hacia quarto, es notable que cada vez hay una mayor cantidad de proyectos que se están iniciando directamente en este nuevo formato. Las nuevas características o desarrollos también estarán centrados directamente sobre quarto, por lo que es importante ir aprendiéndolo desde ahora. Pueden encontrar el desarrollo de como hacer un reporte con Rmarkdown en el Anexo de Reproducibilidad con Rmarkdown
8.1.1 Requisitos
Debido a que Quarto ha sido diseñado para no solamente trabajar con R, su instalación no depende únicamente de un paquete en R, sino que se instala como un software adicional que se puede instalar en: https://quarto.org/docs/get-started/.
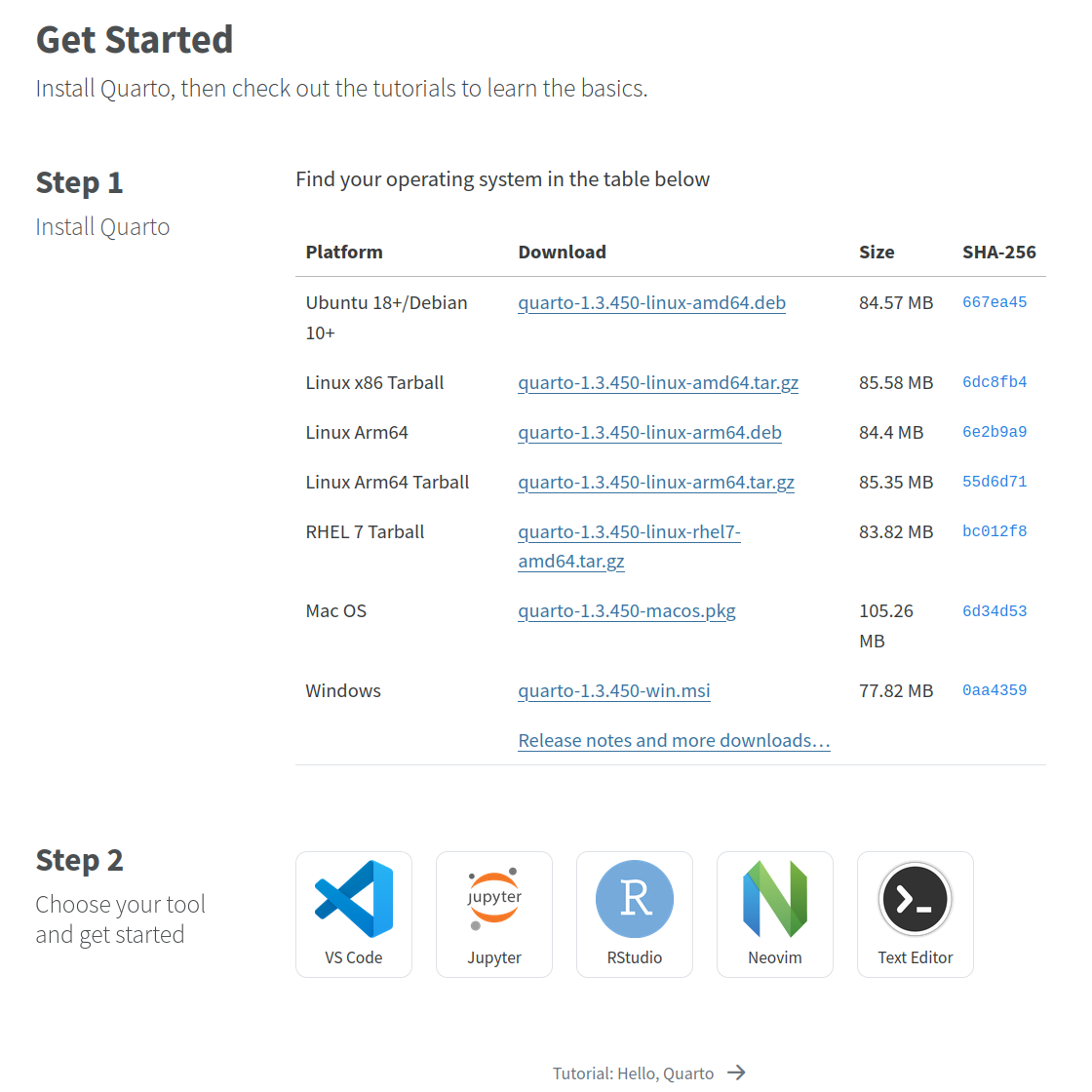
Si se está utilizando una de las últimas versiones de Rstudio, este ya incluye una versión de Quarto precompilado en su instalación, por lo que probablemente no se requeriría hacer la instalación adicional mostrado en las líneas anteriores, aunque es altamente recomendable. Quarto usa Pandoc por debajo para el proceso de compilación para cualquier formato que se desee. Para ejecutar los códigos dentro de los documentos puede usar knitr (Xie 2015) o un kernel jupyter si se quiere hacer desde python o julia por ejemplo. En nuestro caso, que estaremos manejando todo desde R, necesitamos como mínimo tener el paquete knitr instalado:
Además, en el caso que se requiera generar un documento PDF, es necesario también tener instalado una distribución de LaTex. Para los usuarios no experimentados con LaTeX, se recomienda instalar TinyTex, una distribución ligera de LaTeX que se puede obtener desde el mismo R:
install.packages('tinytex')
# Para instalar la distribución:
tinytex::install_tinytex()El paquete tinytex (Xie 2019), con la función install_tinytex(), permite instalar la distribución de LaTeX y configurar automáticamente lo necesario para que no hayan problemas a la hora de compilar documentos a PDF.
Sin embargo, dependiendo de la complejidad del documento que se esté utilizando, uso de fórmulas o paquetes dentro de latex (usuarios mas experimentados), probablemente la distribución minimalista (TinyTeX-1) de tinytext pueda ser insuficiente. En esos casos se recomienda que sea TinyTeX-2:
# Para instalar la distribución TinyTeX-2:
tinytex::install_tinytex(bundle = "TinyTeX-2")8.1.2 Archivos de Quarto
Los archivos de Quarto tienen extensión .qmd. A continuación, se presenta un archivo qmd de ejemplo:
---
title: "Hola Mundo con Quarto"
author: "Nombre, Apellidos"
date: "2023-11-26"
format: html
---
```{r}
#| label: setup
#| include: false
library(ggplot2)
```
## Usando Quarto
### Texto
Los textos pueden usarse con **negrita** o *cursiva*. También es posible
* crear [enlaces](https://quarto.org/)
* incluir expresiones matemáticas como $e=mc^2$ o
$$
y = \beta_0 + \beta_1 x_1 + \beta_2 x_2
$$
Asegúrate de poner un espacio luego de * cuando creas viñetas y un espacio luego de # cuando creas secciones, pero no pongas espacio luego de un $ para una fórmula matemática en-línea.
### Gráficos
Si el código dentro del chunk produce un gráfico, este puede ser mostrando en el archivo resultante/output.
```{r}
#| label: my-plot
#| fig.height: 3
#| fig.width: 5
#| fig.align: center
ggplot(data = cars, aes(speed, dist)) +
geom_point()
```
### Salidas de R
Otra forma de mostrar las salidas de código en R es mostrárlas tal y cual son producidas.
```{r}
model_fit <- lm(dist ~ speed, data = cars)
summary(model_fit)
```
También podemos correr algunas líneas de código en el mismo texto, que al momento de ser renderizado tendrá el valor calculado, como en este caso:
```{r}
b <- coef(model_fit)
```
Por ejemplo, podríamos señalar el coeficiente de regresión: `r b[2]`.
### Formatos de compilación
Este archivo puede ser compilado a HTML, PDF, Word y otros. En Quarto será necesario ir agregando los formatos deseados dentro de la sección `YAML` y la configuación `format:` para los formatos `html`, `pdf` o `docx`.Por lo general, los archivos Quarto tienen los siguientes tres tipos de contenido importantes:
- Una cabecera YAML (opcional) rodeada por los
---. YAML es un formato de serialización de datos que es usado en R Markdown para configurar el aspecto, formato de salida y metadata del documento, como el título, los autores, la fecha, el formato de salida, entre otros. - Bloques de líneas de código de R u otro lenguaje, también llamados chunks, que empiezan con
```{r}y terminan con```. Además, código en línea con el texto que empieza con`ry termina con`. - Texto simple y texto con formato como negrita (
**negrita**), cursiva (*cursiva*) ytexto plano(`texto plano`).´
Al compilar el reporte del ejemplo, obtendremos un documento como el que se muestra en la siguiente figura:
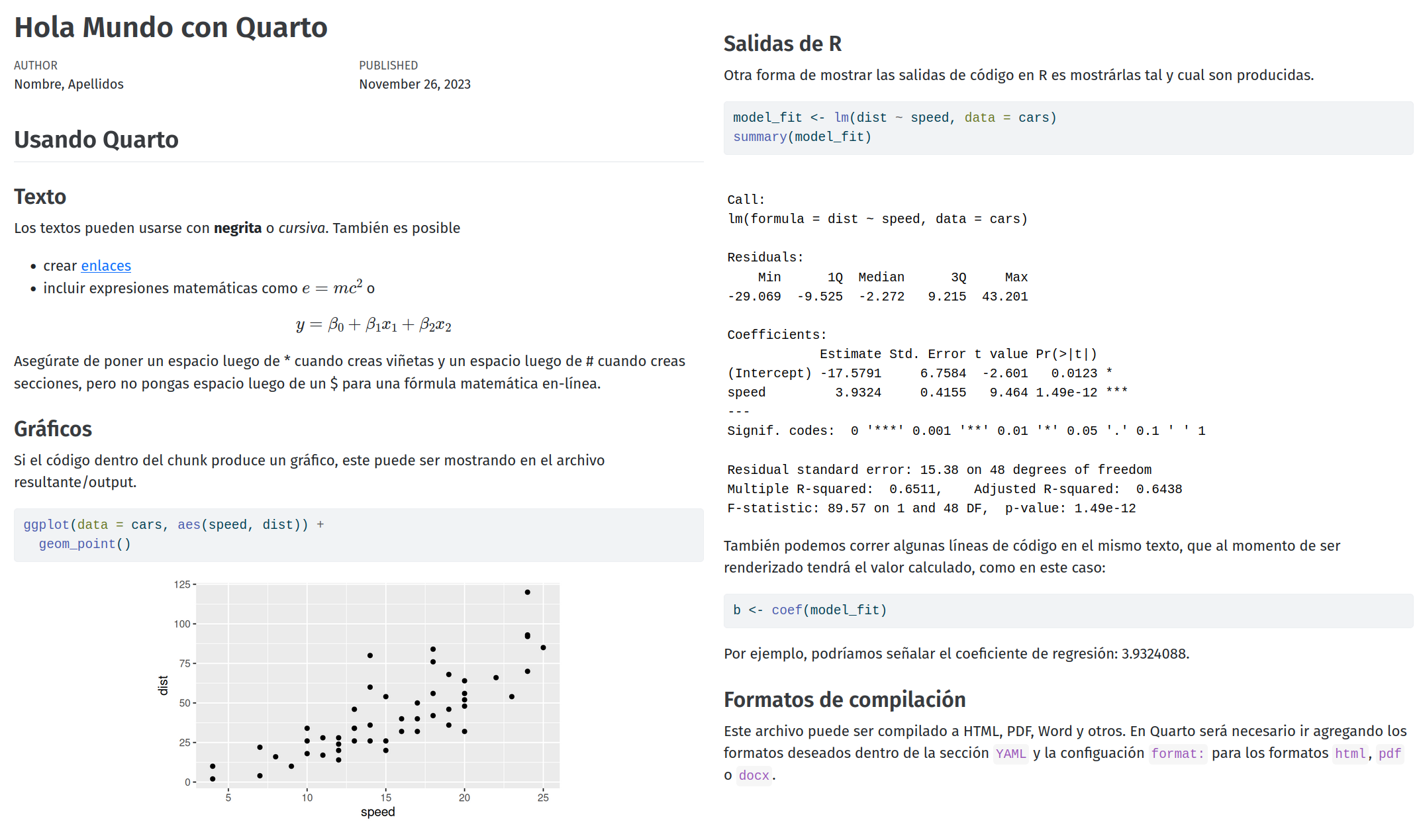
En este reporte se muestran los chunks o bloques de código, pero es posible también esconderlos para generar un reporte dirigido a un público menos técnico. En proyectos donde se utilizan datos intensivamente, QUarto hace que la tarea de actualizar resultados, tablas o gráficos sea sumamente fácil, ya que en la mayoría de los casos solo hay que cambiar el archivo de entrada para que a la hora de compilar el documento, Quarto ejecute los códigos e imprima los nuevos resultados en el reporte.
8.1.3 Compilar un archivo de Quarto
Para generar un reporte a partir de un archivo Quarto hay que dar click al botón Render del panel de edición. También podemos el shortcut Cmd/Ctrl+Shift+K. Otra forma es tener instalado el paquete quarto y ejecutar quarto::quarto_render() o desde la línea de comamdos de la terminal quarto render, pasándo como primer argumento la ruta del archivo a compilar. Esto producirá el reporte en el panel de visualización o en otra ventana, y se creará un archivo con el formato de salida especificado en el directorio donde se encuentra el archivo de Quarto.
Por defecto, a la hora de compilar el documento qmd, el código se ejecutará en una nueva sesión de R. Es decir, se creará una sesión temporal aislada de la sesión de desarrollo donde se ejecutará el código del documento. Si mientras uno va desarrollando el documento qmd va también probando el código y creando objetos, estos no estarán disponibles en la nueva sesión que se cree a la hora de compilar el documento. Por lo tanto, cualquier error que salga a la hora de compilar no estará relacionado con los objetos ya creados en la sesión de desarrollo.
8.1.4 Edición de formato de texto
La edición de formato de textos en archivos Quarto se hace usando la sintaxis de Markdown, el cual es un lenguaje de marcas que consiste en una serie de convenciones de sintaxis para aplicar formato a documentos.
A continuación, veremos cómo dar formato a algunos de los elementos de texto más importantes. RStudio también cuenta con una guía básica de Markdown que se puede obtener con Help > Markdown Quick Reference.
8.1.5 Cabeceras
Las cabeceras o títulos de secciones pueden crearse usando secuencias del símbolo numeral (#). El número de # representa el nivel de la sección. Por ejemplo:
# Primer nivel
## Segundo nivel
### Tercer nivelPor defecto, las cabeceras se enumerarán en el documento compilado. Si se quiere que una cabecera no se enumere, hay que agregar {-} o {.unnumbered} luego de la cabecera:
# Prólogo {-}8.1.6 Énfasis
Se puede dar énfasis al texto con las siguientes sintaxis:
-
cursiva:
*cursiva*o_cursiva_ -
negrita:
**negrita**o__negrita__ -
texto plano:`texto plano`
8.1.7 Hipervínculos
Para incluir hipervínculos, usar la siguiente sintaxis: [etiqueta](link). Por ejemplo [Quarto](https://quarto.org/) produce Quarto.
8.1.8 Listas
Para crear listas ordenadas:
1. Primer ítem
2. Segundo ítem
3. Tercer ítemEsto produce la siguiente lista:
- Primer ítem
- Segundo ítem
- Tercer ítem
Para crear una lista no numerada, se pueden usar los símbolos *, -, o +:
- Ítem
- Ítem
- ÍtemEl resultado es:
- Ítem
- Ítem
- Ítem
Se puede hacer listas con niveles agregando sangrías (dos TAB). Además, es posible combinar lista ordenadas y no numeradas:
1. Primer ítem
- Sub-ítem
- Sub-ítem
2. Segundo ítem
- Sub-ítem
- Sub-ítemEl resultado es el siguiente:
- Primer ítem
- Sub-ítem
- Sub-ítem
- Segundo ítem
- Sub-ítem
- Sub-ítem
8.1.9 Expresiones matemáticas
Se puede añadir expresiones matemáticas al documento usando la sintaxis de LaTeX. Para expresiones en línea con el texto, tenemos que rodearlas con un símbolo de dólar ($). Por ejemplo $f(k) = {n \choose k} p^{k} (1-p)^{n-k}$ produce \(f(k) = {n \choose k} p^{k} (1-p)^{n-k}\). Para insertar expresiones en línea aparte, hay que rodearlas con dos símbolos de dólar ($$). Por ejemplo:
$$
f(k) = {n \choose k} p^{k} (1-p)^{n-k}
$$Produce:
\[ f(k) = {n \choose k} p^{k} (1-p)^{n-k} \]
Además, podemos agregar un identificado a la ecuación para luego referenciarla, agregando #eq- como etiqueta de la expresión justo al final de la ecuación:
$$
f(k) = {n \choose k} p^{k} (1-p)^{n-k}
$$ {#eq-ejemplo}Produce la Ecuación 8.1:
\[ f(k) = {n \choose k} p^{k} (1-p)^{n-k} \tag{8.1}\]
También es posible añadir estructuras matemáticas más complejas dentro de $ o $$. Por ejemplo, para añadir una matriz de 4x4:
$$
\begin{array}{ccc}
x_{11} & x_{12} & x_{13}\\
x_{21} & x_{22} & x_{23}
\end{array}
$$\[ \begin{array}{ccc} x_{11} & x_{12} & x_{13}\\ x_{21} & x_{22} & x_{23} \end{array} \]
Se recomienda revisar el wikibook LaTeX/Mathematics como referencia para la sintaxis de LaTeX para expresiones matemáticas.
8.1.10 Chunks
Los chunks o bloques de código son la característica principal de los documentos de Quarto. Permiten insertar y ejecutar código en el mismo documento. Para insertar un chunk podemos
- Usar el shortcut
Cmd/Crtl+Alt+I, - Dar click en ‘Insert a new code chunk’ en el panel de edición.
- Escribir manualmente los delimitadores
```{r}y```.
Para ejecutar un chunk, damos click en el botón Run en la parte superior del editor o usamos el shortcut Cmd/Ctrl+Shift+Enter. RStudio ejecuta el código y muestra los resultados en línea. Al igual que en un script de R, para correr una línea de código dentro del chunk se usa Cmd/Ctrl + Enter.
8.1.10.1 Nombramiento
Los chunks pueden nombrarse usando la sintaxis ```{r nombre} o también indicándolo con label:
```r
#| label: nombre
```Nombrar a los chunks tiene las siguientes ventajas:
- Podemos navegar fácilmente a un chunk específico usando el navegador de código en la parte inferior izquierda del editor.
- Los gráficos que produzcan los chunks van a tener nombres únicos que luego se pueden utilizar en otra parte del documento.
- Se puede configurar una serie de chunks para que estén almacenados en caché para prevenir volver a correr procesos computacionalmente costosos.
Existe un nombre de chunk que produce un comportamiento especial: setup. A la hora de compilar el documento, el chunk llamado setup se correrá solo una vez, antes de cualquier otro chunk.
8.1.10.2 Opciones locales
Los chunks tienen opciones locales que permiten configurar el comportamiento de cada chunk. Estas opciones se incluyen como argumentos dentro de las cabeceras ```{r} de cada chunk o indicándolas con #|. Hay casi 60 opciones que se pueden usar, y aquí mencionaremos solo las más importantes. Para ver la lista completa, se puede recurrir a http://yihui.name/knitr/options/.
Las opciones más importantes controlan si un chunk es ejecutado o no y qué resultados son incluidos en el reporte compilado:
-
echo=FALSE: Muestra el resultado pero no el código. -
eval=FALSE: Previene que un bloque de código sea ejecutado. Eso es útil para mostrar código de muestra o para deshabilitar un bloque de código sin tener que comentar cada línea. -
include=FALSE: Ejecuta el código, pero no muestra el código o resultado en el documento final. Esto es útil para el chunk de setup. -
message=FALSEowarning=FALSE: Previene que mensajes o advertencias se impriman en el reporte final, respectivamente. -
results='hide': Esconde los resultados. -
collapse=TRUE: Colapsa el código y la salida en un único bloque.
8.1.10.3 Opciones globales
Para configurar las opciones de todos los chunks en el archivo podemos llamar a knitr::opts_chunk$set() en un chunk, preferentemente el de setup. Por ejemplo, para colapsar los códigos y sus resultados cada uno en un solo bloque en todo reporte, podemos usar collapse = TRUE:
knitr::opts_chunk$set(collapse = TRUE)Si se quisiera esconder todo el código en el documento, podemos usar echo = FALSE:
knitr::opts_chunk$set(echo = FALSE)No es muy recomendable asignar message=FALSE y warning=FALSE como opciones globales, ya que esto hace más difícil depurar errores.
8.1.11 Código en línea con el texto
Para agregar código de R en línea con el texto podemos usar `r `. Por ejemplo, para poner cuántas observaciones tiene la base de datos mtcars, podemos tipear `r nrow(mtcars)`. Cuando se compile el documento se imprimirá el resultado: 32.
8.1.12 Tablas
Por defecto, R Markdown imprime data frames y matrices como se imprimirían en la consola:
mtcars %>%
filter(mpg > 20) mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2Si se quisiera mostrar las tablas con un mejor formato, podemos usar la función kable() del paquete knitr:
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Merc 240D | 24.4 | 4 | 146.7 | 62 | 3.69 | 3.190 | 20.00 | 1 | 0 | 4 | 2 |
| Merc 230 | 22.8 | 4 | 140.8 | 95 | 3.92 | 3.150 | 22.90 | 1 | 0 | 4 | 2 |
| Fiat 128 | 32.4 | 4 | 78.7 | 66 | 4.08 | 2.200 | 19.47 | 1 | 1 | 4 | 1 |
| Honda Civic | 30.4 | 4 | 75.7 | 52 | 4.93 | 1.615 | 18.52 | 1 | 1 | 4 | 2 |
| Toyota Corolla | 33.9 | 4 | 71.1 | 65 | 4.22 | 1.835 | 19.90 | 1 | 1 | 4 | 1 |
| Toyota Corona | 21.5 | 4 | 120.1 | 97 | 3.70 | 2.465 | 20.01 | 1 | 0 | 3 | 1 |
| Fiat X1-9 | 27.3 | 4 | 79.0 | 66 | 4.08 | 1.935 | 18.90 | 1 | 1 | 4 | 1 |
| Porsche 914-2 | 26.0 | 4 | 120.3 | 91 | 4.43 | 2.140 | 16.70 | 0 | 1 | 5 | 2 |
| Lotus Europa | 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.90 | 1 | 1 | 5 | 2 |
| Volvo 142E | 21.4 | 4 | 121.0 | 109 | 4.11 | 2.780 | 18.60 | 1 | 1 | 4 | 2 |
Si quisieramos que las tablas tengan también una numeración de forma similar a cómo sucedió con las ecuaciones, podemos agregar un label con el prefijo tbl- y un nombre a la tabla (tbl-cap:) como parte de la configuración del chunk, para obtener a Tabla 8.1:
```{r}
#| label: tbl-mtcars-example
#| tbl-cap: Un data frame
mtcars %>%
filter(mpg > 20) %>%
knitr::kable()
```| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Merc 240D | 24.4 | 4 | 146.7 | 62 | 3.69 | 3.190 | 20.00 | 1 | 0 | 4 | 2 |
| Merc 230 | 22.8 | 4 | 140.8 | 95 | 3.92 | 3.150 | 22.90 | 1 | 0 | 4 | 2 |
| Fiat 128 | 32.4 | 4 | 78.7 | 66 | 4.08 | 2.200 | 19.47 | 1 | 1 | 4 | 1 |
| Honda Civic | 30.4 | 4 | 75.7 | 52 | 4.93 | 1.615 | 18.52 | 1 | 1 | 4 | 2 |
| Toyota Corolla | 33.9 | 4 | 71.1 | 65 | 4.22 | 1.835 | 19.90 | 1 | 1 | 4 | 1 |
| Toyota Corona | 21.5 | 4 | 120.1 | 97 | 3.70 | 2.465 | 20.01 | 1 | 0 | 3 | 1 |
| Fiat X1-9 | 27.3 | 4 | 79.0 | 66 | 4.08 | 1.935 | 18.90 | 1 | 1 | 4 | 1 |
| Porsche 914-2 | 26.0 | 4 | 120.3 | 91 | 4.43 | 2.140 | 16.70 | 0 | 1 | 5 | 2 |
| Lotus Europa | 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.90 | 1 | 1 | 5 | 2 |
| Volvo 142E | 21.4 | 4 | 121.0 | 109 | 4.11 | 2.780 | 18.60 | 1 | 1 | 4 | 2 |
Para mayor información sobre la configuración de estas tablas, revisar la documentación de la función con ?knitr::kable.
El paquete kableExtra (Zhu 2021) es una extensión que permite un control más avanzado para el diseño de tablas. Otros paquetes con funcionalidades más avanzadas son gt (Iannone, Cheng, y Schloerke 2022), flextable (Gohel 2022) y huxtable (Hugh-Jones 2022).
8.1.13 Figuras
Por defecto, las figuras se mostrarán justo debajo de los chunks con las que fueron generadas. Usando las opciones locales o globales, podemos mostrar o no el código de estos chunks (echo). Otras opciones de chunk útiles para generar figuras son:
-
fig.widthyfig.height: Controlan el ancho y el alto de las figuras (en pulgadas, por defecto), respectivamente. Por ejemplo,fig.width = 8yfig.height = 9producen una figura con 8 pulgadas de ancho y 6 pulgadas de alto. Si se quiere usar otra unidad, podemos pasar la medida y la unidad entre comillas. Por ejemplo,fig.width = '8cm'yfig.height = '9cm'producen una figura de 8 cm de ancho y 6 cm de alto. -
out.widthyout.height: Controlan la relación de aspecto de la figura en el reporte compilado. Por ejemplo, para que se imprima la figura con el 50% del ancho original pero conservando la relación de aspecto ponemosout.width='50%'. -
fig.align: Controla la alineación de la figura. Puede tomar los valores'right','left'y'center'. -
fig.caption: Permite ponerle un título a la figura. Por ejemplo,fig.caption = 'Una figura'.
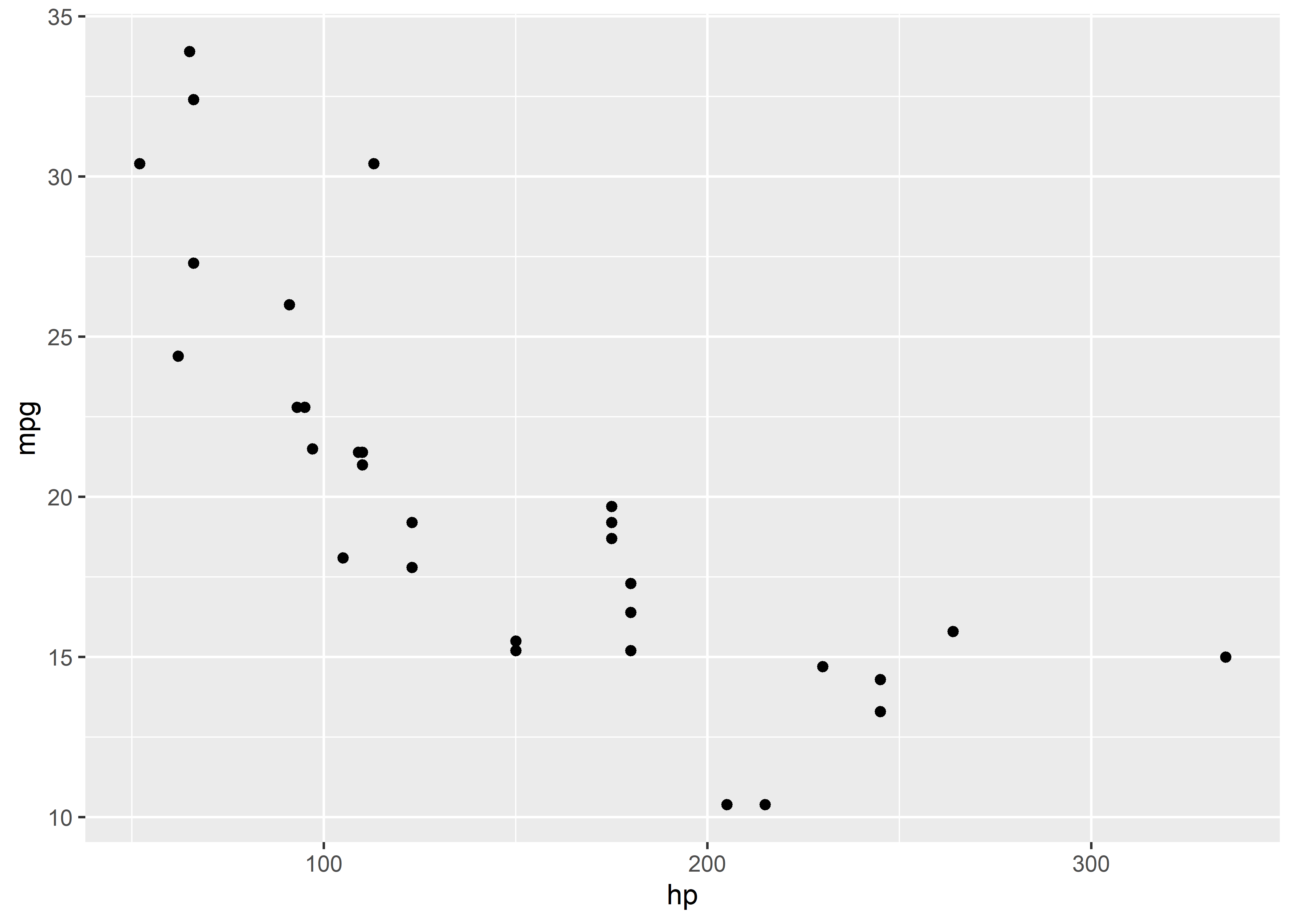
Veamos, como ejemplo, el siguiente chunk con las opciones por defecto:
```{r}
ggplot(mtcars, aes(hp, mpg)) +
geom_point()
```
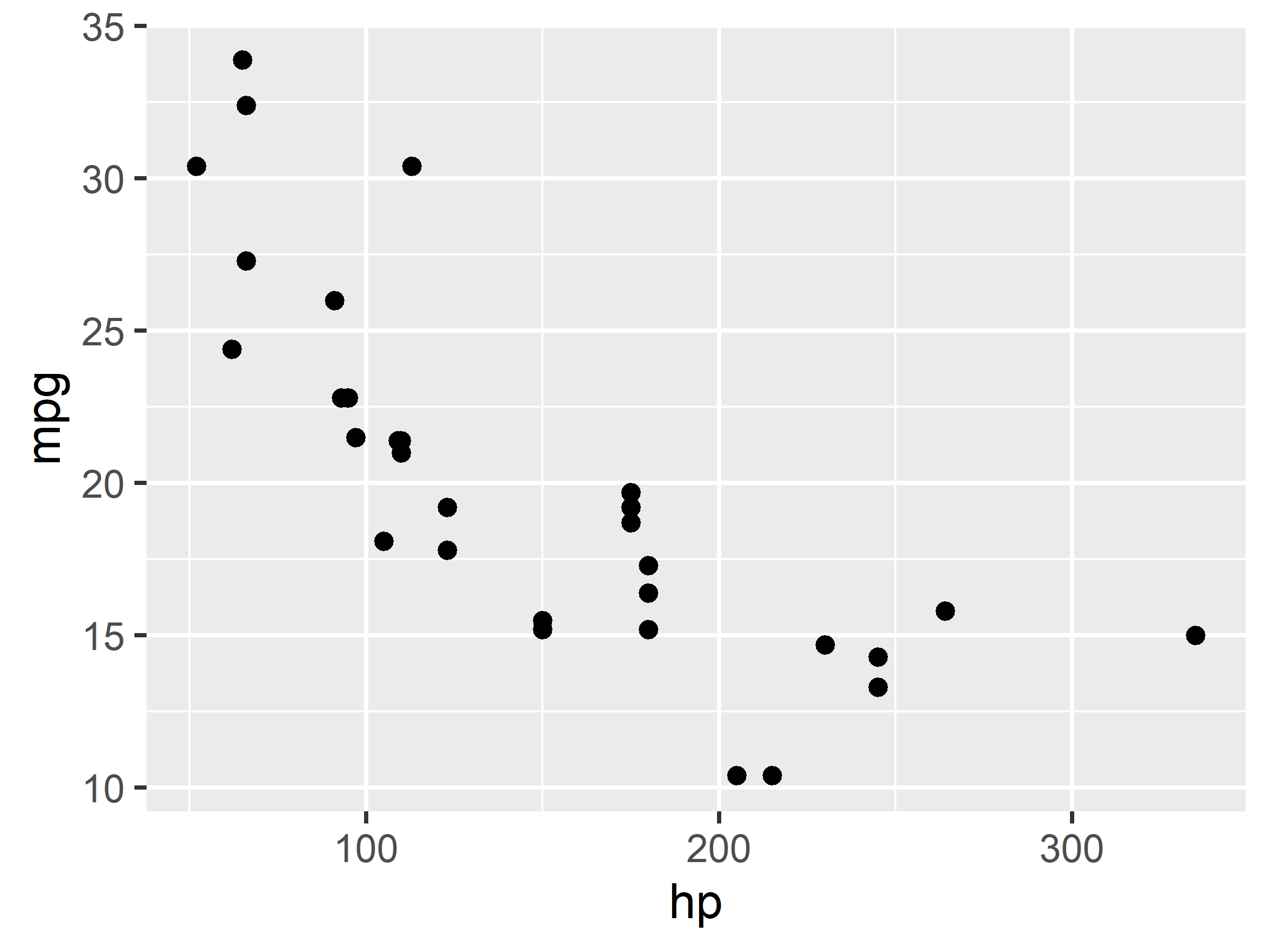
Ahora, configuremos el tamaño y la alineación, y agreguemos un título a la Figura 8.2:
```{r}
#| label: fig-mtcars-example
#| fig.width: 4.0
#| fig.height: 3.0
#| fig.align: center
#| fig.cap: Una figura
ggplot(mtcars, aes(hp, mpg)) +
geom_point()
```
Para insertar una figura externa que no se genera en el mismo documento con código en R, podemos usar la función knitr::include_graphics(). Por ejemplo:
knitr::include_graphics('figures/cat.jpg')
8.1.14 Metadata y control del documento
Podemos controlar el aspecto, formato de salida y metada del documento usando una cabecera con sintaxis YAML, el cual es un formato de serialización de datos.
Al crear un documento Quarto con RStudio, este nos solicitará alguna metadata para el documento, como el título, el autor, la fecha y el formato de salida. También podemos elegir la opción de crear un documento vacío.
En el caso de que hayamos suministrado la metadata, RStudio creará un documento R Markdown nuevo con la siguiente cabecera en formato YAML:
---
title: "Untitled"
author: "Diego Villa"
date: "2024-05-28"
output: html_document
---En las siguiente secciones veremos opciones para cambiar o agregar metadata en el documento Quarto.
8.1.14.1 Título y subtítulo
Para especificar el título y subtítulo usamos title y subtitle. Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
---8.1.14.2 Autor(es)
Para especificar uno o varios autores usamos la opción author y listamos a los autores con comas:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
---8.1.14.3 Fecha
Para especificar la fecha, usar la opción date. Es posible ingresar una fecha manualmente como texto, por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "10 de octubre de 2022"
---También podemos insertar una fecha dinámica usando código de R línea que devuelva la fecha en la que se compila el documento. La función en R que permite hacer esto es Sys.date(), la cual devuelve la hora del sistema. Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "2024-05-28"
---Cabe resaltar que Sys.Date() devuelve la fecha en formato ‘%Y-%m-%d’ (Year-month-day, por ejemplo: 2022-10-10). Para cambiar el formato podemos usar la función format() sobre Sys.Date() y especificar como argumento el formato deseado. Por ejemplo, format(Sys.time(), '%d %B, %Y') devuelve la fecha en formato 10 October, 2022. En la cabecera se vería así:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
---Podemos referirnos a este blog para una guía rápida de la sintaxis para dar formato a las fechas en R.
8.1.14.4 Formato de salida
El formato de salida se puede especificar usando la opción format. Por defecto, el formato de salida es html, es decir, en formato HTML. Algunos otros formatos de salida son:
- PDF:
pdf - Word:
docx - Latex:
keep-tex: true
format:
pdf:
keep-tex: truePara una lista más extensa sobre todos los formatos posibles disponibles y soportados por quarto, se puede consultar el siguiente enlace: https://quarto.org/docs/output-formats/all-formats.html
8.1.14.5 Tabla de contenidos
Se puede agregar una tabla de contenidos en el reporte usando la opción toc y especificando la profundidad de los encabezados mediante toc_depth. Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
format:
html:
toc: true
toc_depth: 2
---Si toc_depth no se especifica, por defecto se mostrarán 3 niveles de encabezados.
8.1.15 Tabla de contenidos flotante
Podemos usar la opción toc_float para que la tabla de contenidos sea flotante (separada del texto) y aparezca a la izquierda. En este caso, cuando estemos navegando por el documento, la tabla de contenidos siempre va a ser visible.
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
format:
html:
toc: true
toc_float: true
---Opcionalmente, se puede especificar una lista de opciones para toc_float que controlen su comportamiento. Entre estas opciones están:
toc-expand(TRUEpor defecto): Controla si es que la tabla de contenidos muestra solo los encabezados de nivel superior. Si se colapsa, la tabla de contenidos se expande automáticamente en línea cuando sea necesario.smooth-scroll(TRUEpor defecto): Controla si los desplazamientos de página se animan cuando se navega por los elementos de la tabla de contenidos mediante clics.
Por ejemplo:
---
title: "Título"
subtitle: "Subtítulo"
author: "Diego Villa, Kasandra Ascuña"
date: "28 Mayo, 2024"
output:
html_document:
toc: true
toc_float: true
toc-expand: true
smooth-scroll: true
---8.1.16 Más información
Para más información sobre Quarto, podemos referirnos a la web https://quarto.org/docs/ o capítulos de libros como el de R for Data Science.
8.1.17 Ejercicios
Para estos ejercicios utilizaremos el conjunto de datos del archivo fev.csv para generar un reporte con Quarto. Este conjunto de datos contiene parte de las observaciones del estudio realizado por Tager et al. (1979), quienes investigaron el efecto del tabaquismo de los padres en la función pulmonar de sus hijos en East Boston, Massachusetts. Este archivo de datos fue recuperado del repositorios de datos de Rosner (2015). El conjunto de datos contiene observaciones hechas a 654 niños y jóvenes de 3 a 19 años sobre la edad (age), el volumen espiratorio forzado (litros) entre 25% y 75% de la capacidad vital (fev), la altura (hgt), el sexo (sex), y si fuma habitualmente o no (smoke).
Siga las siguientes indicaciones para generar un reporte con el análisis del conjunto de datos del archivo fev.csv:
- Cree un archivo Quarto y modifique la metadata de la cabecera YAML agregando título, nombre de autor y fecha.
- Luego de la cabecera, inserte un chunk de setup donde se llame al paquete tidyverse.
- Cree las secciones de Lectura de datos, Procesamiento de datos, y Análisis exploratorio de datos.
- En la sección de Lectura de datos, incluya el código para leer el archivo
fev.csv. - En la sección de Procesamiento de datos realice las siguientes operaciones:
- Revise las variables que contiene el conjunto de datos. (Pista: Usar
str(),summary()y/odplyr::glimpse()) - Remueva la variable
id. - Si es que fuera necesario, eliminar las observaciones vacías.
- Convierta la variable
smokeen factor y agregue las etiquetas (labels) para los niveles0:"Non-current smoker"y1:"Current smoker". - Convierta la variable
sexen factor y agregue las etiquetas para los nivles0:Femaley1:Male. - Cree una factor con grupos de edades con los siguiente niveles ordenados: de 3 a 4 años (
"3-4"), 5 a 9 años ("5-9"), 10 a 14 años ("10-14"), y 15 a 19 años ("15-19").
- Revise las variables que contiene el conjunto de datos. (Pista: Usar
- En la sección de Análisis exploratorio de datos, realizar los siguientes análisis:
- Generar una tabla cruzada entre el status de fumador (
smoke) y el sexo (sex) con los porcentajes en cada grupo. (Pista: Usarjanitor::tabyl()) - Calcule el promedio del volumen espiratorio (
fev) por grupo etario. - Calcule el promedio del volumen espiratorio en los grupos de fumadores y no fumadores.
- Generar un gráfico de cajas para el volumen espiratorio por grupo etario.
- Modificar el gráfico anterior para distinguir el color de las cajas según estatus de fumador (Pista: Usar
fill). - Modificar el gráfico anterior para generar facetas (gráficos separados) por sexo (Pista: Usar
facet_wrap).
- Generar una tabla cruzada entre el status de fumador (
- Compilar el reporte en HTML.
8.2 Control de cambios con git
Cuando desarrollamos un proyecto de análisis, tenemos distintos procesos que realizamos como la importación de datos, limpieza de datos, generación de sub-conjuntos de datos a compartir, análisis y modelos estadísticos, así como la generación de tablas y gráficos. Todos estos procesos no siempre siguen un proceso lineal y en secuencia; en ocasiones, es necesario corregir la forma de limpieza, implementar cambios adicionales o regresar al cómo se había hecho dicho análisis en algún punto en el tiempo (hace 1 mes por ejemplo). Y si este proyecto de análisis no ha sido desarrollado exclusivamente por una persona sino por un equipo, entonces la posibilidad de regresar y/o recuperar códigos o procesos de análisis será tortuoso en caso no hayamos usado alguna plataforma de control de cambios.
Git, permite resolver este problema. Es un sistema de control de cambios que permite:
- Registrar cambios de archivos binarios y textos planos. En el caso de archivos de texto plano (script, rmd, quarto, csv), se puede registrar cambios línea por línea.
- Crear ramas (branch) que permiten ir desarrollando procesos independientes de un mismo proyecto (por ej. limpieza y aparte los códigos para análisis), sin generar conflictos entre los archivos o que uno de los analistas deba esperar que el otro termine de modificar para recién empezar a trabajar sobre ello.
- Explorar los cambios hechos en cada archivo mientras se haya realizado el registro correctamente (commits).
- Regresar en el tiempo y restaurar archivos o códigos tal y cual se encontraban en un momento en específico.
8.2.1 Git y Github
Git es un sistema que tiene un funcionamiento local, es decir, que todos los registros de cambios, y demás características mencionadas se desarrollan en la computadora de quien lo usa, especificamente en una carpeta (repositorio) de trabajo. En el directorio de trabajo habrá una carpeta oculta llamada .git donde se almacenan todos los registros necesarios para que el sistema de control de cambios funcione.
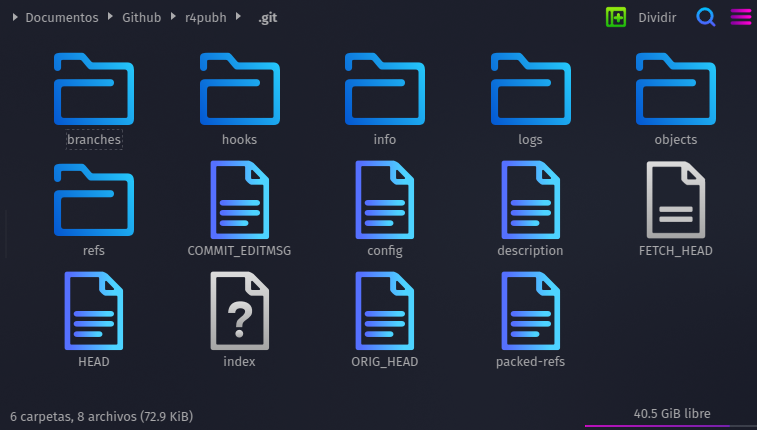 Sin embargo, no es la única manera de funcionar. Hay diversas implementaciones de git en la web, para que además de que los controles de cambios se registren en local, también puedan hacerlo en remoto. Una de las implementaciones más conocidas es Github y Gitlab, siendo este último más reciente; y el primero, el más popular y de mayor frecuencia de elección para el alojamiento de los repositorios.
Sin embargo, no es la única manera de funcionar. Hay diversas implementaciones de git en la web, para que además de que los controles de cambios se registren en local, también puedan hacerlo en remoto. Una de las implementaciones más conocidas es Github y Gitlab, siendo este último más reciente; y el primero, el más popular y de mayor frecuencia de elección para el alojamiento de los repositorios.
Github, al igual que otras implementaciones web, ofrecen algunas características adicionales que de por sí, no se encuentra en la versión local de git:
- Creación y manejo de Issues: Esto es la creación de un hilo de problema, solicitud o inconveniente en el repositorio. Puede utilizarse para reportar un bug, solicitar una nueva característica en el repositorio o indicar algún inconveniente en el uso de algo en específico, como por ej. una función que no se está comportando como debería.
- Documentación con wiki: Esta sección permite crear una documentación más extensa sobre el uso de lo que se esté alojando en el repositorio. Por ejemplo, si el repositorio fuese de un paquete en R, se podría usar el wiki para documentar la instalación, usos, ejemplos y aplicaciones del paquete, casi como un tutorial o guía de este.
- Sección de discusiones: Esta implementación es relativamente reciente en github y su objetivo es separar de los Issues, los hilos que tengan como propósito discutir rumbos del proyecto, cronogramas, recursos, o enfoques de resolver un problema en específico. Podría primero tenerse un hilo en la sección de discusiones, que luego termine en un Issue en específico que resolverá un problema directo.
- Github pages: Esta implementación, permite que cuando se tenga una página web estática, github pueda disponerlo públicamente bajo el link: user.github.io/repositorio . Es una forma fácil y sencilla de poder compartir un proyecto o análisis realizado con Rmarkdown o Quarto por ejemplo.
-
Github actions: Por último, esto permite encargar tareas recurrentes y programadas al servidor de github. Por ejemplo, si tuvieramos un proyecto de webscrapping, se podría programar un github actions, para que ejecute el scrapeo cada 8 horas, y que automáticamente actualice un archivo
.csven función de ello.
8.2.2 Creación de repositorio
Veamos un ejemplo de uso de un proyecto git en github. Para poder realizar este procedimiento sin problemas, se requiere que tengamos una cuenta creada en github: https://github.com/signup?source=login. Aunque desde Rstudio podemos manejar fácilmente repositorios git y github, existe un software del mismo github para poder realizar esto y que también mostraremos en esta sección: https://desktop.github.com/.
Hay 2 maneras de poder hacer la creación de un proyecto para luego poder tenerlo alojado en Github:
- Primero crear el repositorio de forma local y luego subirlo a Github generando que se cree un nuevo repositorio.
- Crear el repositorio en github, y luego clonarlo en el local, de tal manera que nuestro directorio ya estaría ligado a github.
Veamos ambas maneras:
-
Repositorio local: La forma más sencilla en la que podemos realizar esto es creando un proyecto con Rstudio:
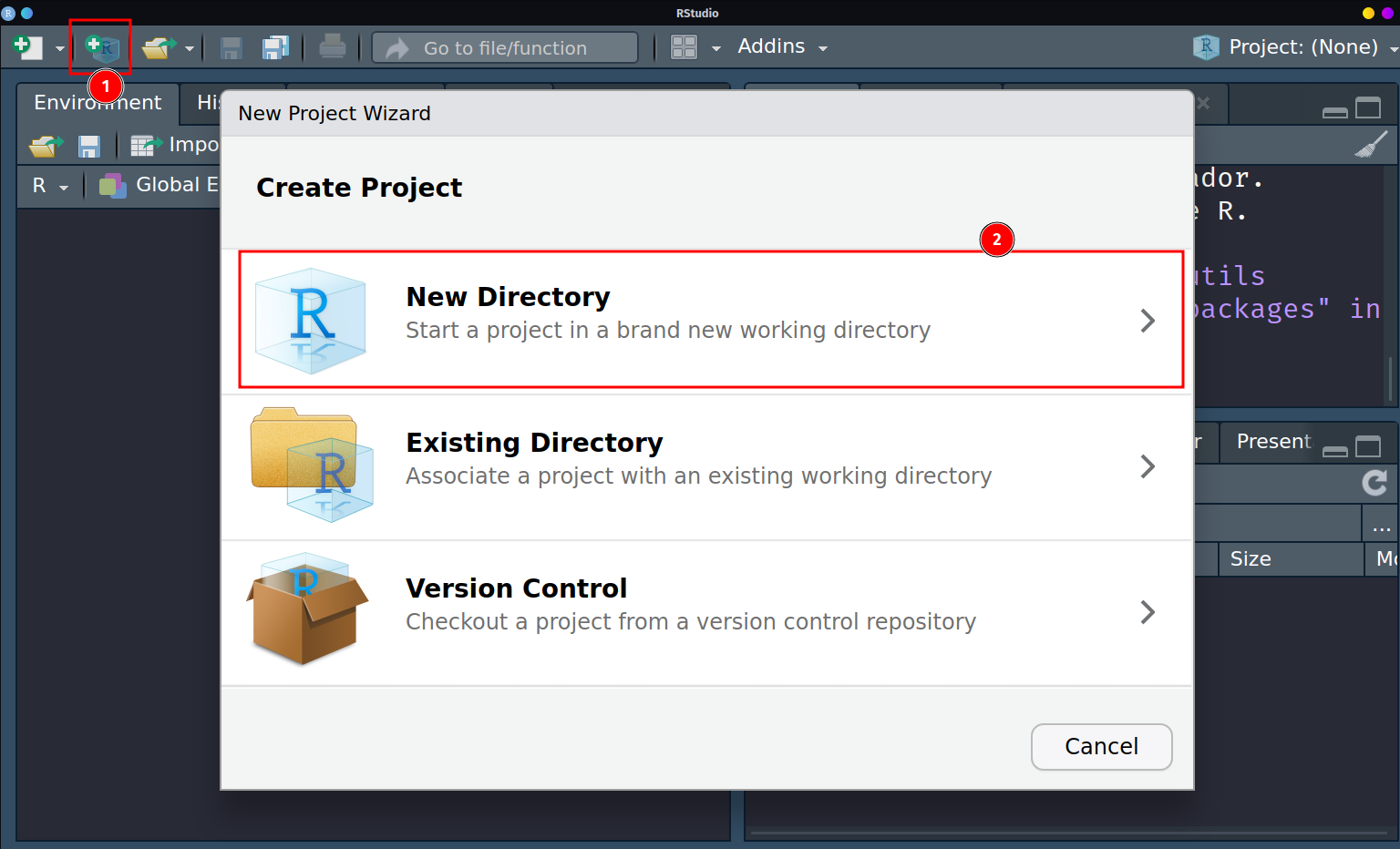
Figura 8.4: Creación de un Proyecto con Rstudio
El cuál creará una carpeta y nos preguntará si queremos marcar check en Create a git repository y Use renv with this project.
{#fig-creacion-proyecto-git}Una vez que se realizó la creación del proyecto en base a lo anterior, veremos que en el panel de Environment ahora aparece una pestaña llamada git que permitirá poder hacer un seguimiento de los archivos creados y que aún no se han registrado (commit).
{#fig-repo-git-creado}-
La otra manera es hacer la creación en un inicio desde Github, para luego clonar el repositorio en el local. Para ello vamos directamente a github habiendo ya ingreso a nuestras cuentas creadas previamente: https://github.com/organizations/healthinnovation/repositories/new
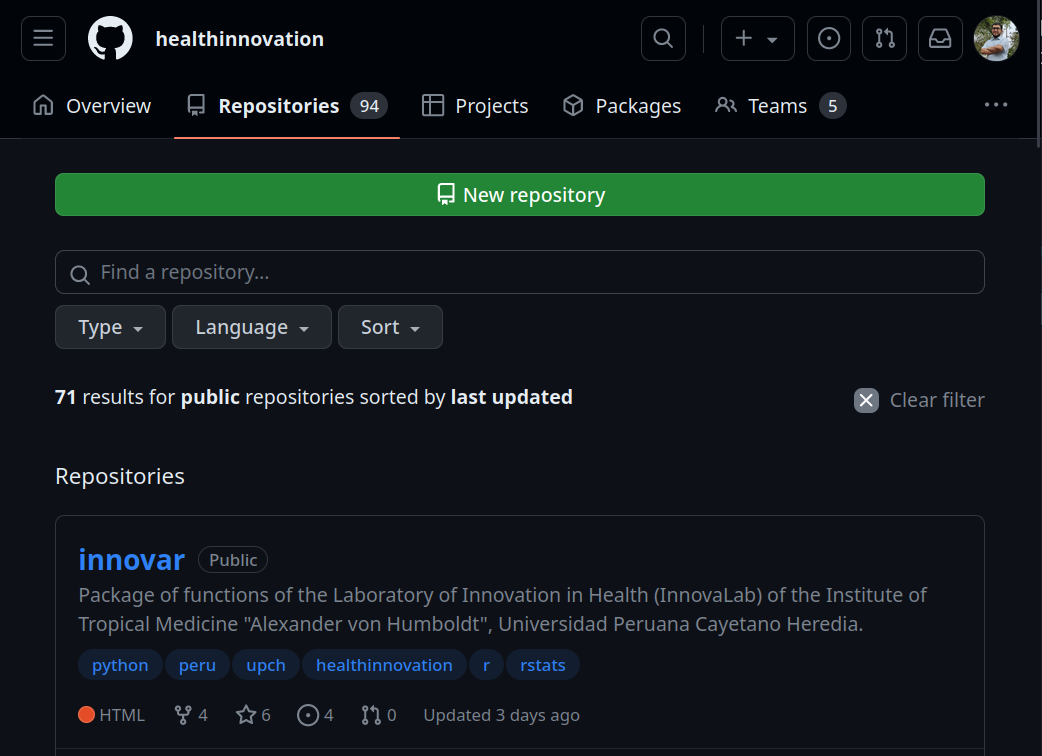
Figura 8.5: Creación de un repositorio desde Github 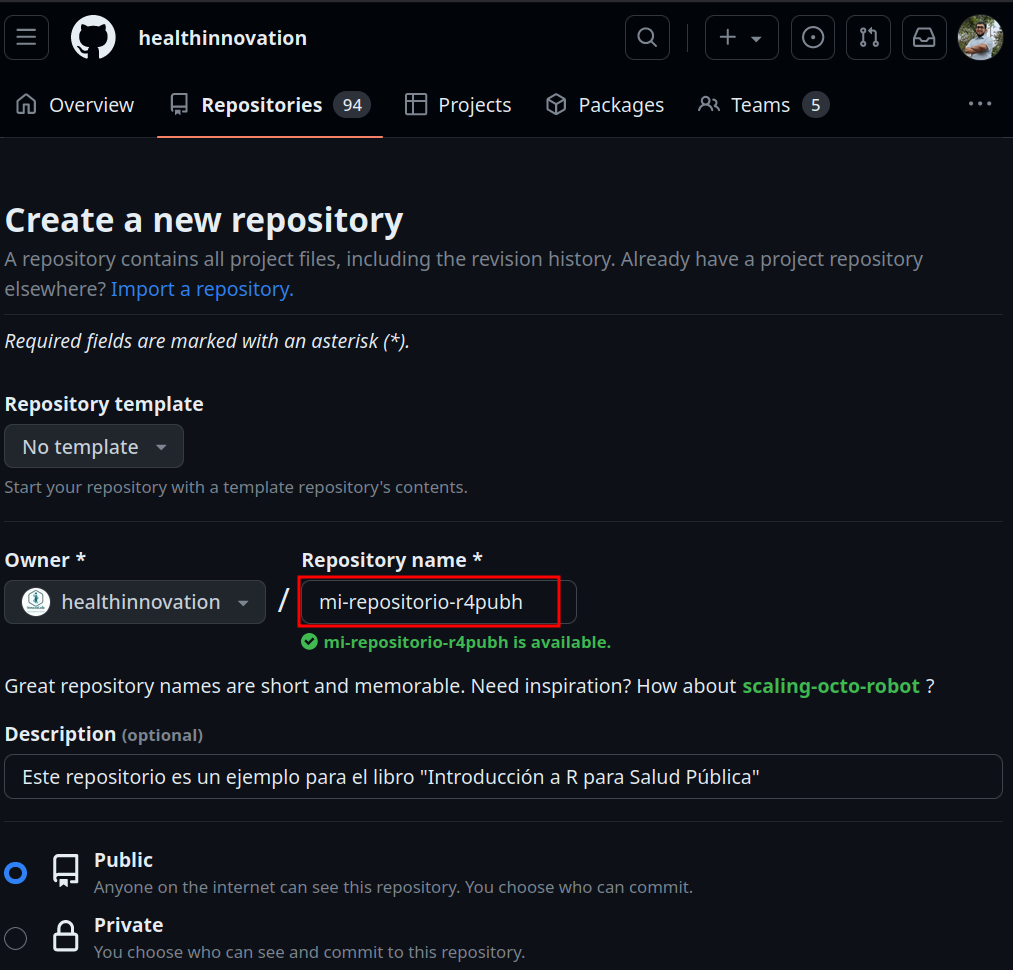
Figura 8.6: Configuración de nombre y descripción de repositorio en Github 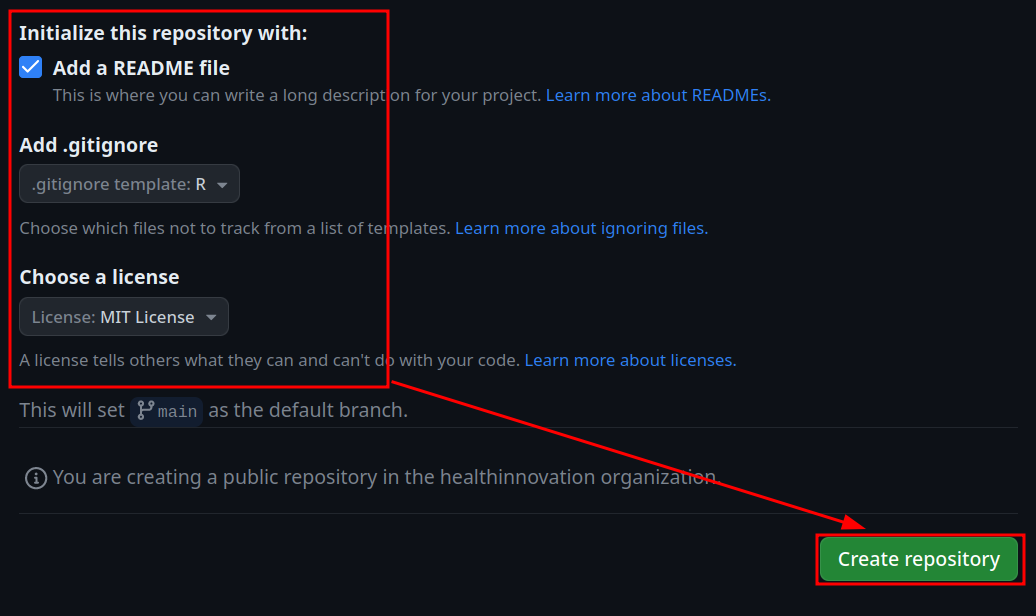
Figura 8.7: Configuración de readme, gitignore y licencia en Github
Toda la información necesaria sobre el proyecto en Github que necesitemos para poder luego trabajar con el se encuentra aquí:
{#fig-creacion-repo-github-4}Una vez creado el repositorio en Github, tenemos que clonarlo localmente. Esto se puede lograr desde la terminal del sistema operativo y comando bash usando git clone https://github.com/user/repo.git o mediante la función de creación de proyectos de Rstudio, de forma similar a la Figura 8.4, con la diferencia que en lugar de seleccionar New Directory seleccionaremos Version Control:
{#fig-clonar-repo-rstudio-1 width="659"}\
{#fig-clonar-repo-rstudio-2}Ahora en la siguiente imagen se observa que rstudio nos solicita 3 informaciones:
- Repository URL: Esto es el link hacia github donde se encuentra nuestro repositorio creado. Usaremos el mismo repositorio que creamos anteriormente. La forma de acceder a esta información se puede observar en la @fig-creacion-repo-github-4
- Project directory name: Esto es nombre que tendrá la carpeta donde se encuentren todos los archivos dentro del repositorio. Habitualmente se crea con el mismo nombre que tiene el repositorio creado, pero esto siempre puede modificarse a elección.
- Create project as subdirectory of: Esto es similar a la forma de creación de proyecto que vimos en la @fig-creacion-proyecto-git, donde se tiene que indicar el nombre de la carpeta donde se alojará el proyecto (que tiene a su vez una carpeta más).
{#fig-clonar-repo-rstudio-3}
{#fig-clonar-repo-rstudio-4}
{#fig-clonar-repo-rstudio-5}Y de esta manera tendríamos ya nuestro repositorio tanto en Github como de forma local para poder trabajar con el.
8.2.3 Registro de cambios
Una vez que el repositorio se encuentra creado, ya podemos trabajar nuestro proyecto de análisis en el, desde crear un archivo script, rmarkdown o quarto, hasta ir codificando los proceso de importación, limpieza, modelamiento y/o visualización de datos. Cada uno de estos procesos se traduce en un cambio en nuestros archivos.
Desde git, cualquier cambio en la estructura o conformación de los archivos se traduce en un cambio registrable, y esto puede abarcar desde 100 nuevas líneas de código ingresados en un archivo o nuevas base de datos que ingresan en el proyecto, hasta la simple acción de agregar un espacio en un código en uno de los tantos archivos que puedan haber en un proyecto. Una buena práctica en git es registrar y nombrar los cambios conformen vayan teniendo sentido en nuestro proyecto. A continuación se muestran algunos ejemplos de cambios que valdría la pena registrar en un proyecto:
Desarrollo del análisis exploratorio de las variables
Actualización de la base de datos X
Corrección de la codificación para la visualización
Mejora en el archivo readme
Corrección ortográfica a la explicación del análisis
Es importante que se registren tantos cambios como procesos involucren un proyecto y no registrar un único cambio que trae consigo modificación en muchos archivos y líneas de código a la vez sin un único propósito claro. Dicho de otra manera, es mucho mejor tener 8 registros de cambios (commits) que tener un único commit que tenga 8 modificaciones importantes en el.
Ahora, veremos un ejemplo de modificación en el repositorio de ejemplo que creamos previamente:
Crearemos un archivo quarto y lo nombraremos
analisis_preliminar.qmd. Notaremos que al momento de guardar el archivo en la sección de git de Rstudio aparecen listados 2 archivos a lado de un símbolo de interrogación en color amarillo. Esto implica que Rstudio está detectando 2 cambios nuevos desde la creación del repositorio.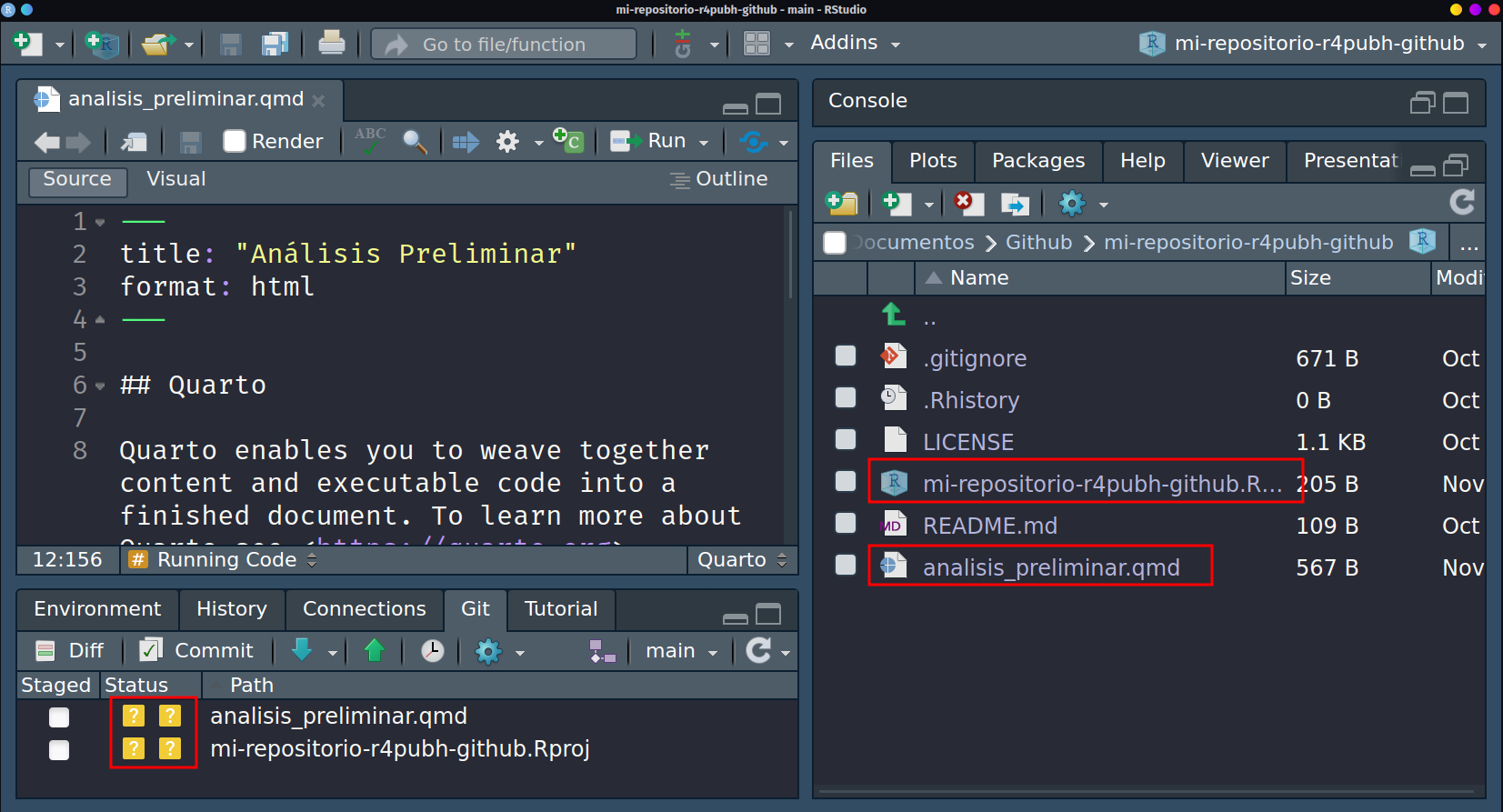
Ahora, haremos algunas modificaciones en el archivo simulando de que estamos desarrollando un proceso de análisis.
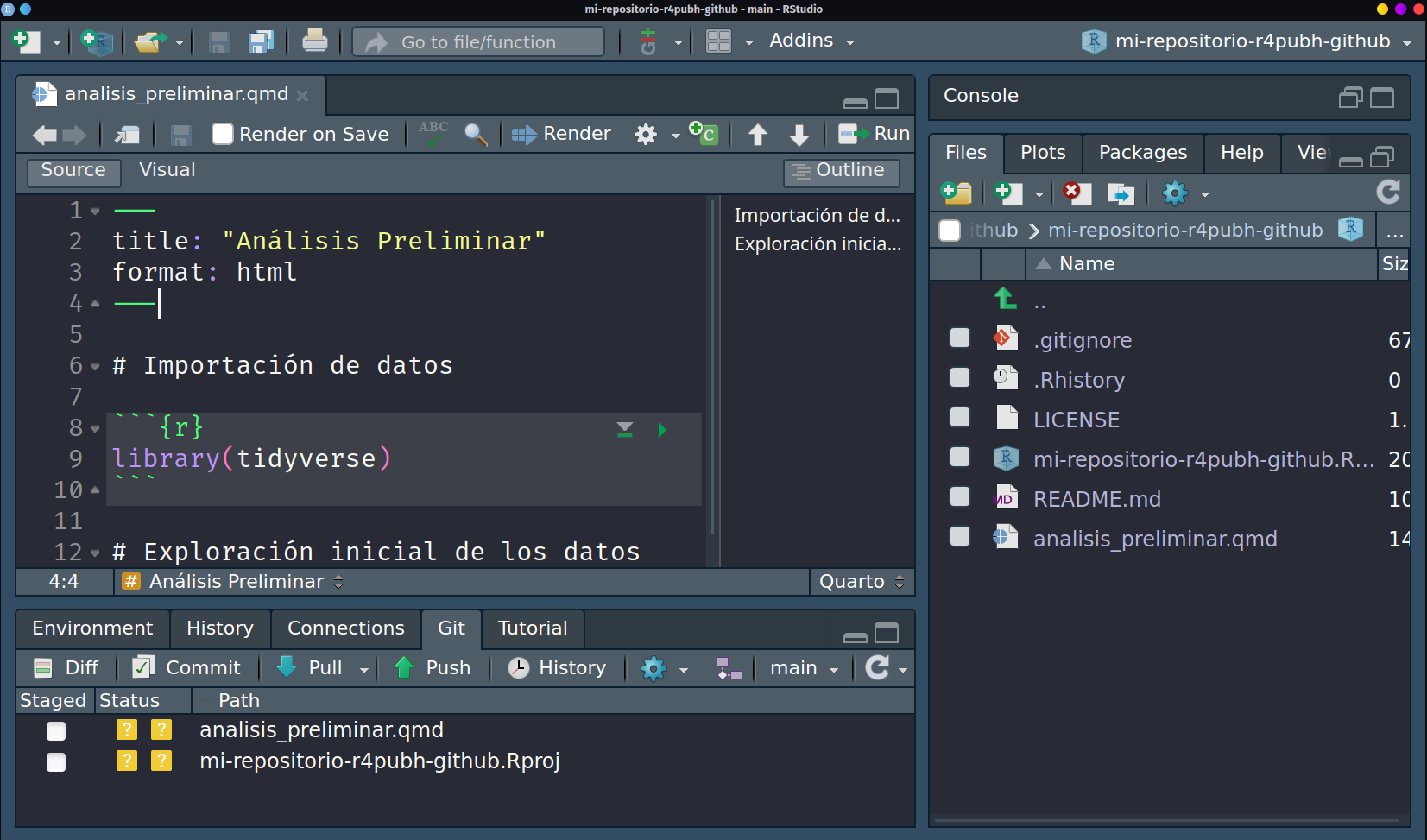
-
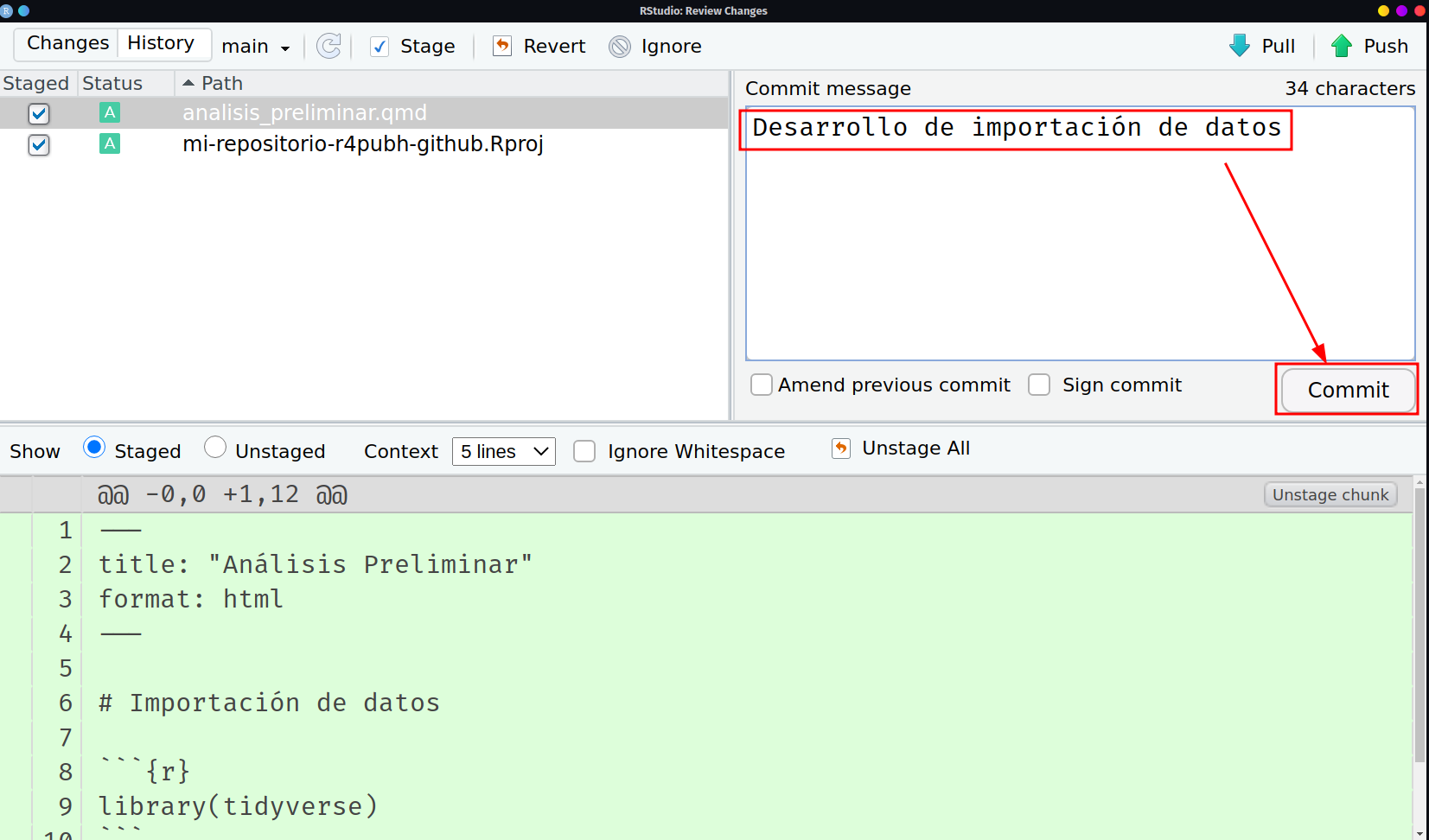
Una vez hemos simulado el tener una codificación sobre la importación de datos, tenemos un cambio sustantivo que vale la pena registrar antes de seguir escribiendo o modificando cosas adicionales. Seleccionaremos dando check en las cajitas tal y como se muestra en la imagen y dando click donde
Commit.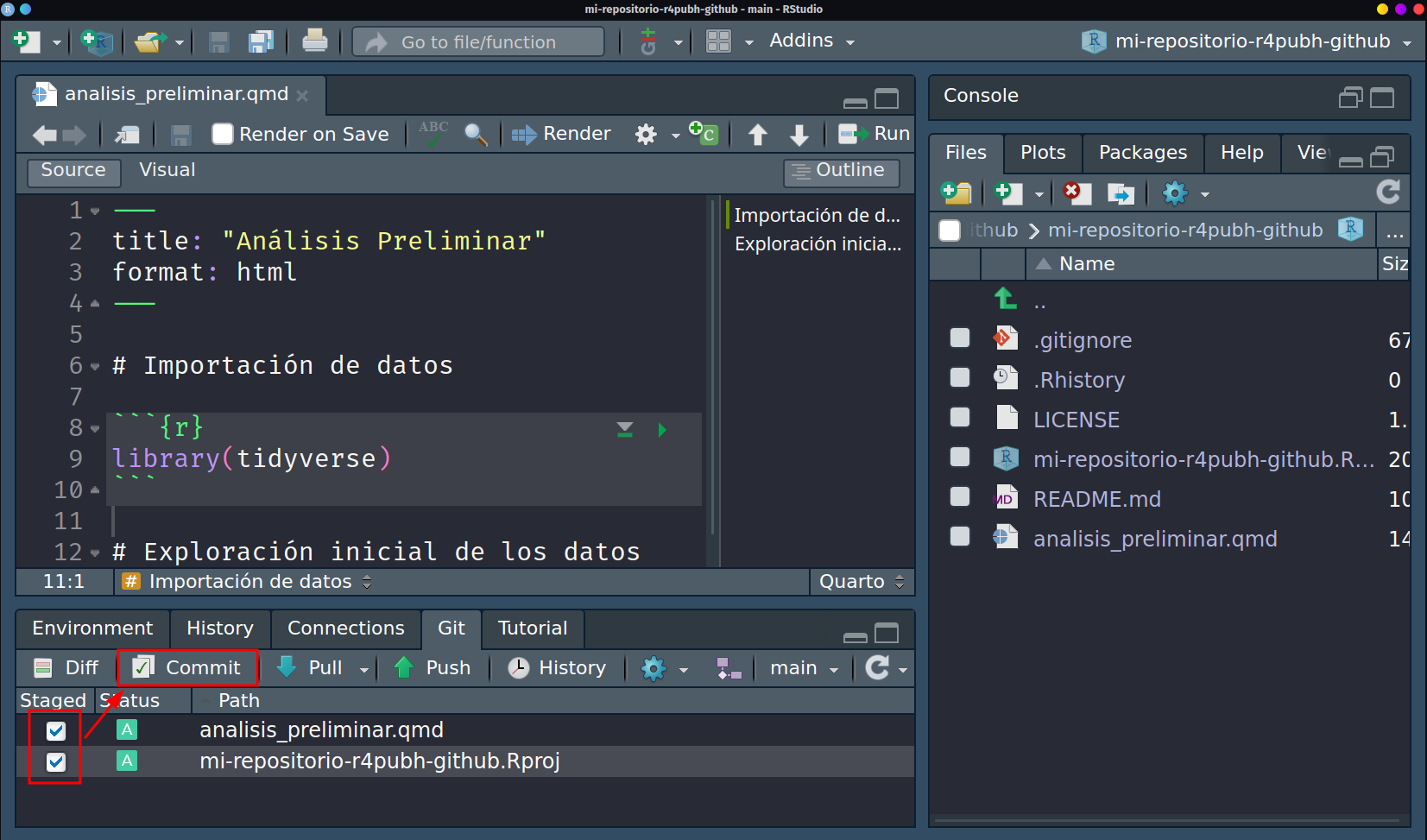
Selección de archivos modificados para commit -
Una vez realizado ello, se abrirará un panel de Rstudio con 4 apartados principales: una barra de herramientas con algunas opciones más avanzadas de git; un panel medio dividido en 2 que muestra a lado izquierdo los archivos que se registrarán para commit y a lado derecho el mensaje que llevará el commit así como el botón para hacerlo; y en la parte de abajo, se mostrarán los cambios del archivo que esté seleccionado arriba. En este caso, los cambios están pintados en su totalidad en verde ya que se trata de un archivo totalmente nuevo, por lo que todo su contenido es un cambio en sí.
Selección de archivos modificados para commit Una vez dado click en
Commitse mostrará un mensaje que resume un mensaje de git que indica que los commits fueron registrados correctamente.
Selección de archivos modificados para commit Esto podremos comprobarlo también porque al momento de regresar a Rstudio, observaremos que ya no se encuentran los archivos que registramos previamente, y se advierte un mensaje de
Your branch is ahead of 'origin/main' by 1 commit, que indica que el commit se ha registrado correctamente y falta subirlo al repositorio.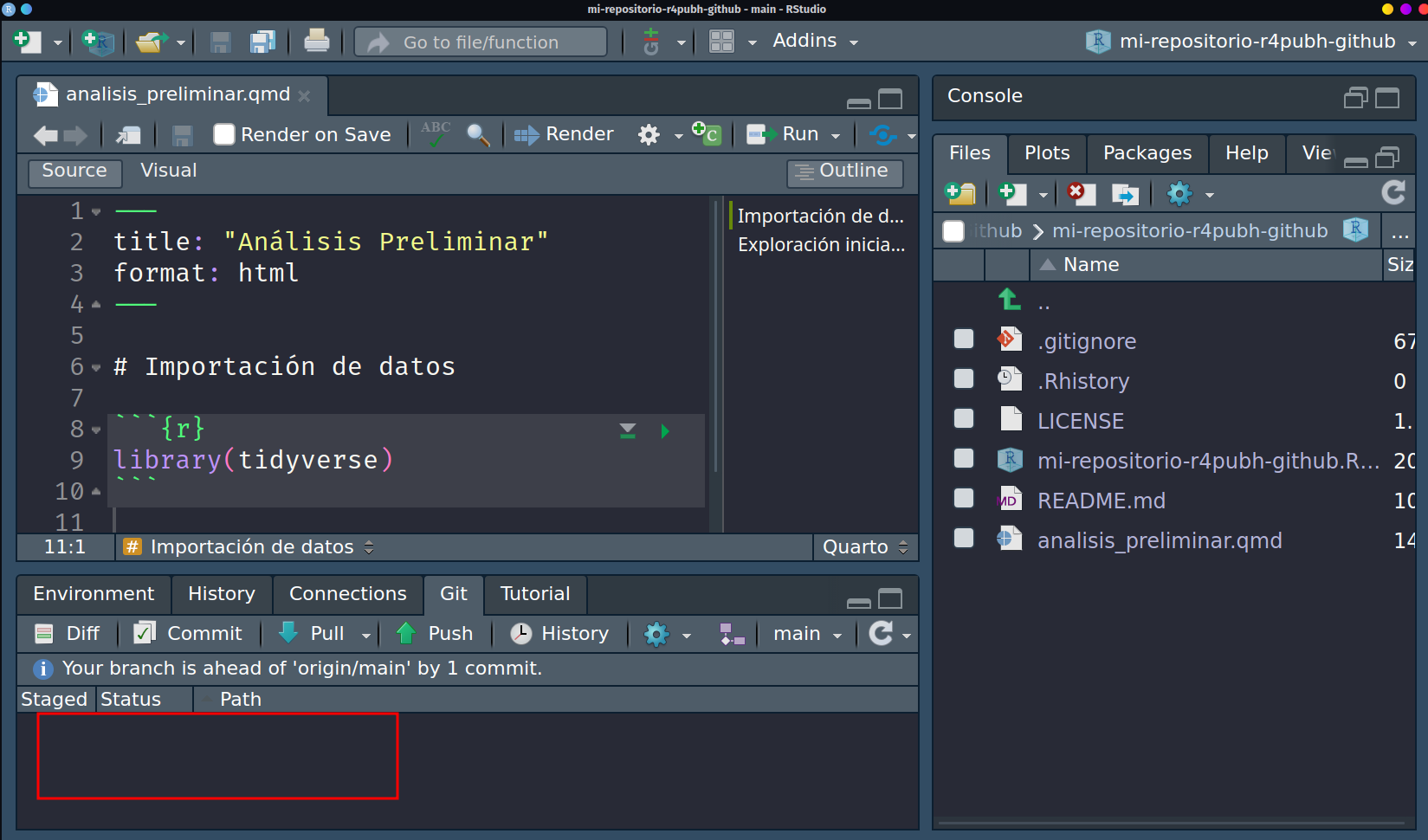
Selección de archivos modificados para commit -
La idea de la dinámica mostrada es que una vez realizado el commit, sigamos codificando, creando archivos o corrigiendo cosas previas, pero cada vez que hagamos un cambio sustantivo, registremos esos cambios con un commit. Por ejemplo si desarrollaramos el análisis exploratorio de los datos:
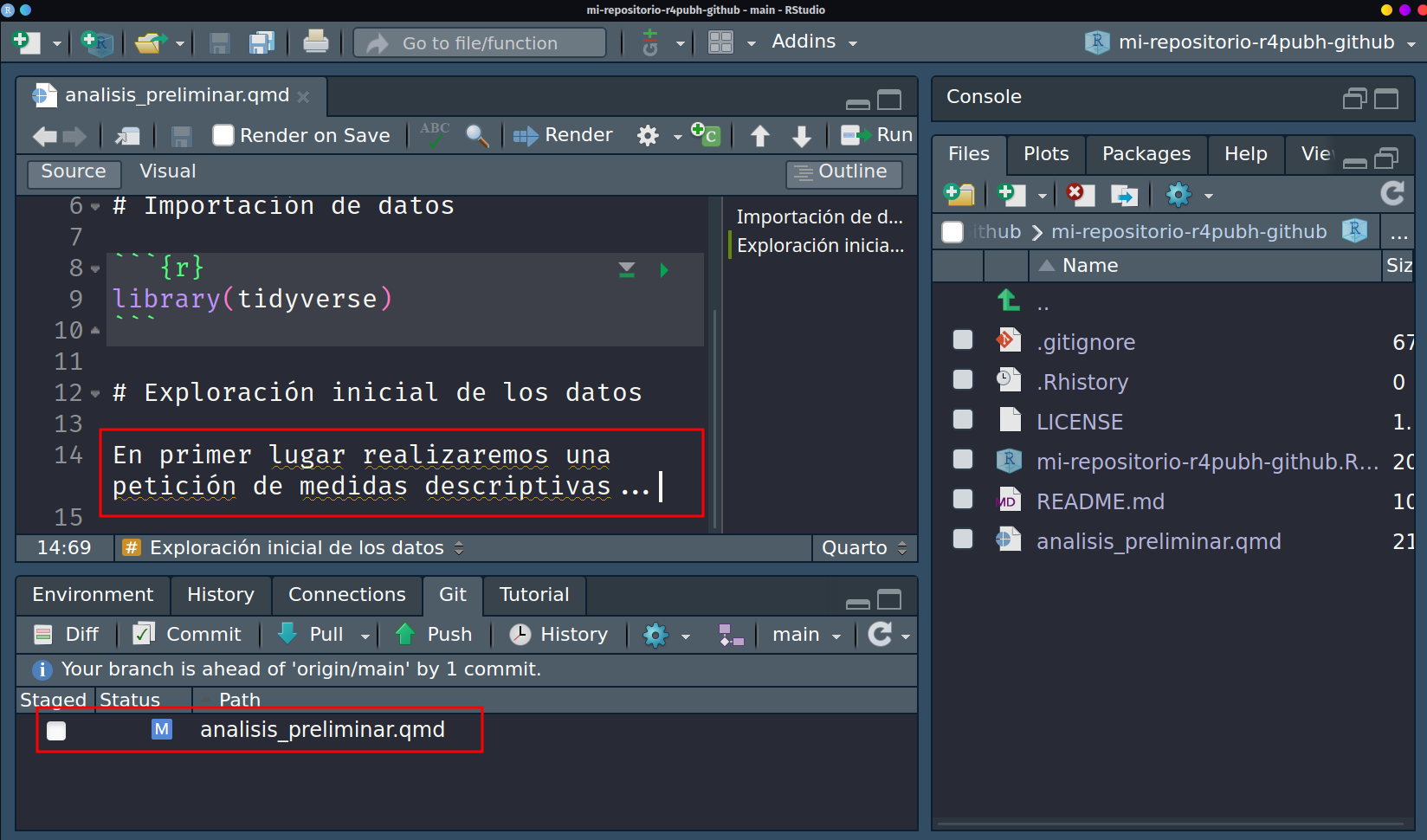
Selección de archivos modificados para commit Tal y como señalamos en el paso previo, registramos el cambio y nombramos nuestro commit. Esta vez podremos observar en el panel inferior de que el texto en verde solo es en 2 líneas que son las únicas que han cambiado con respecto al commit anterior. En caso hubiese borrado en lugar de agregado, la línea estaría sombreada en color rojo.
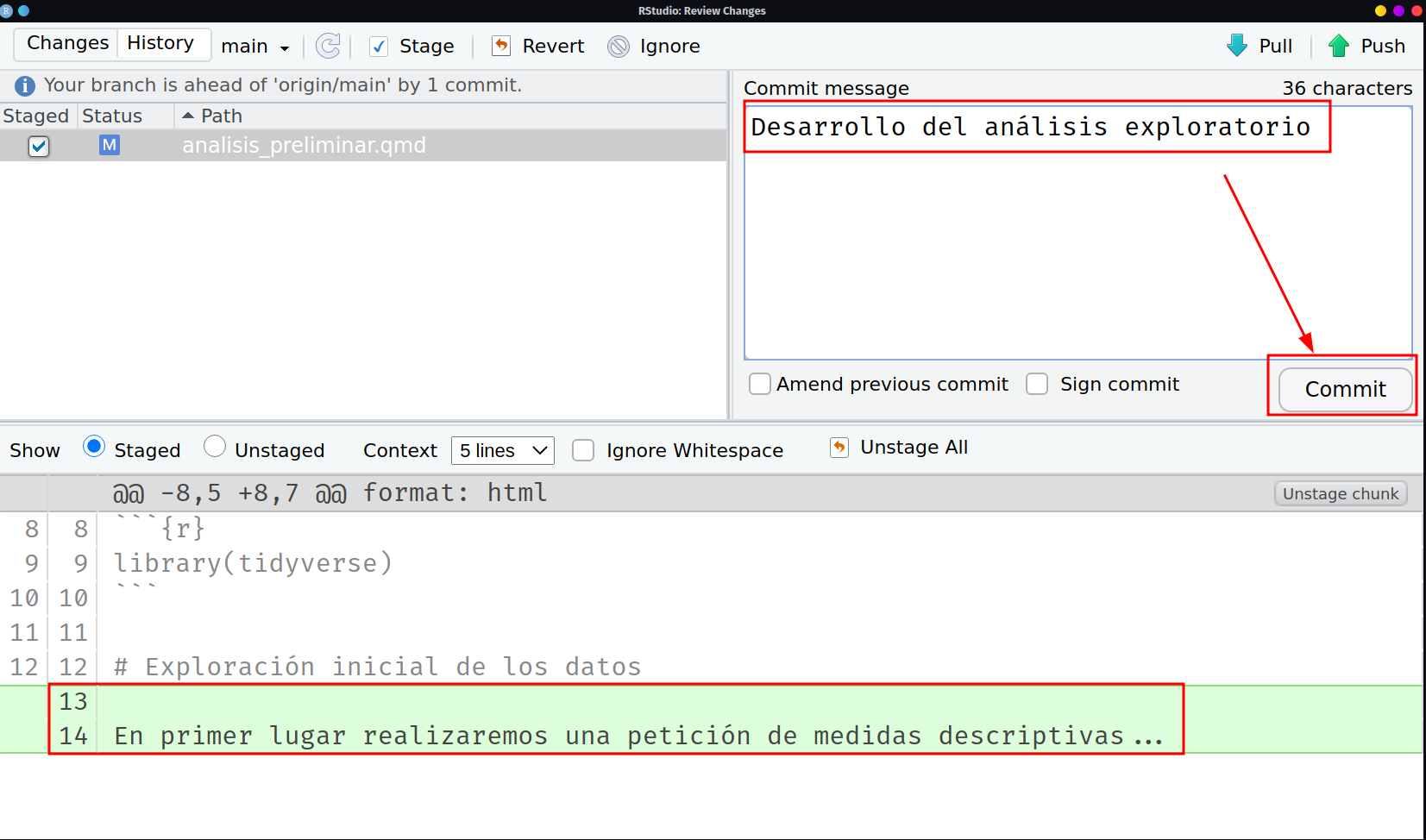
Selección de archivos modificados para commit
8.2.4 Envío de cambios al repositorio
Cuando hacemos commits, tendremos todos los cambios registrados de forma local en nuestra carpeta de archivos, sin embargo, si vamos al repositorio (github), podremos observar que no se muestra ningún cambio desde la creación del repositorio:
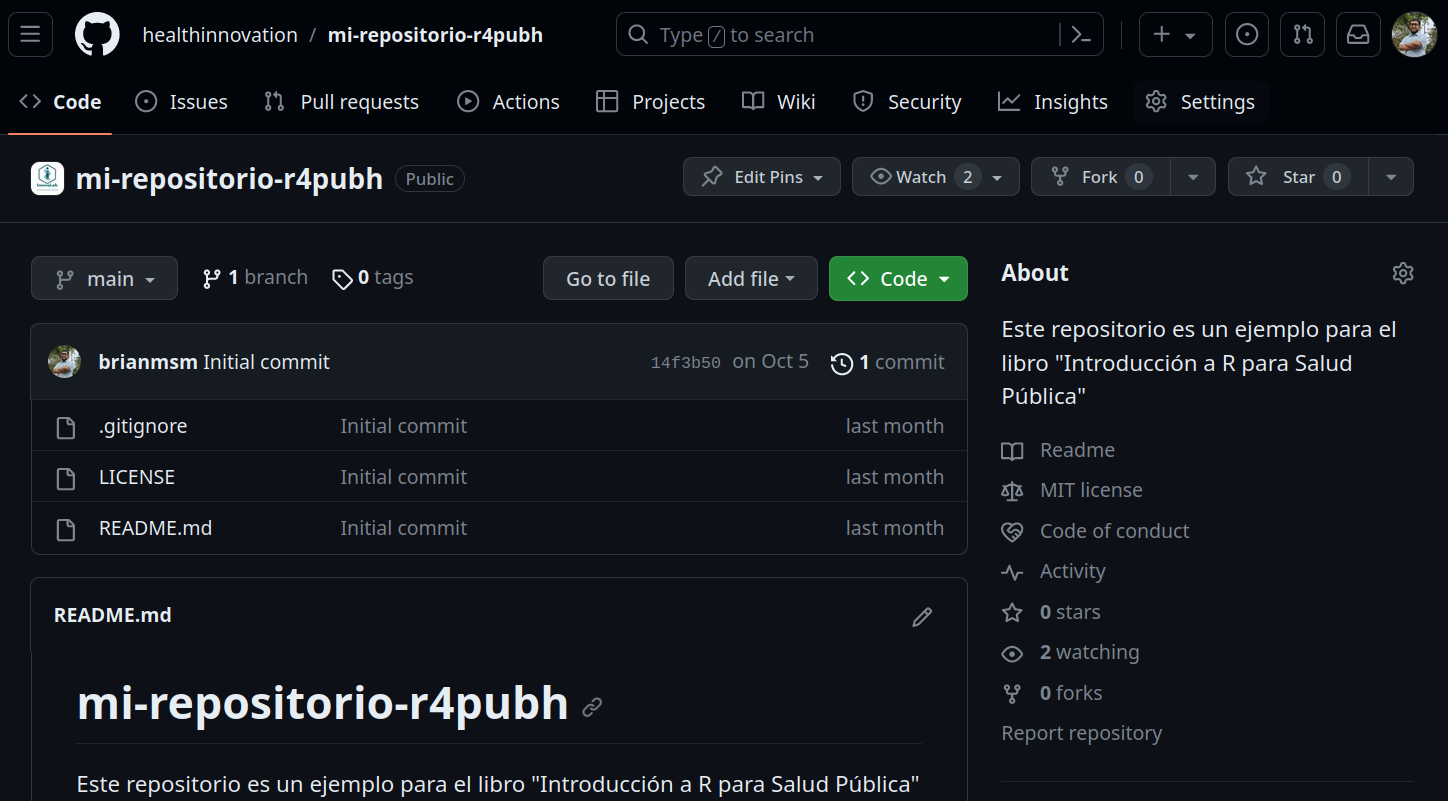
Esto no significa que nuestros cambios no hayan sido guardados, sino que no han sido enviados al servidor/repositorio aún. De hecho, podemos verificar nuestros commits en local, dando click en history.
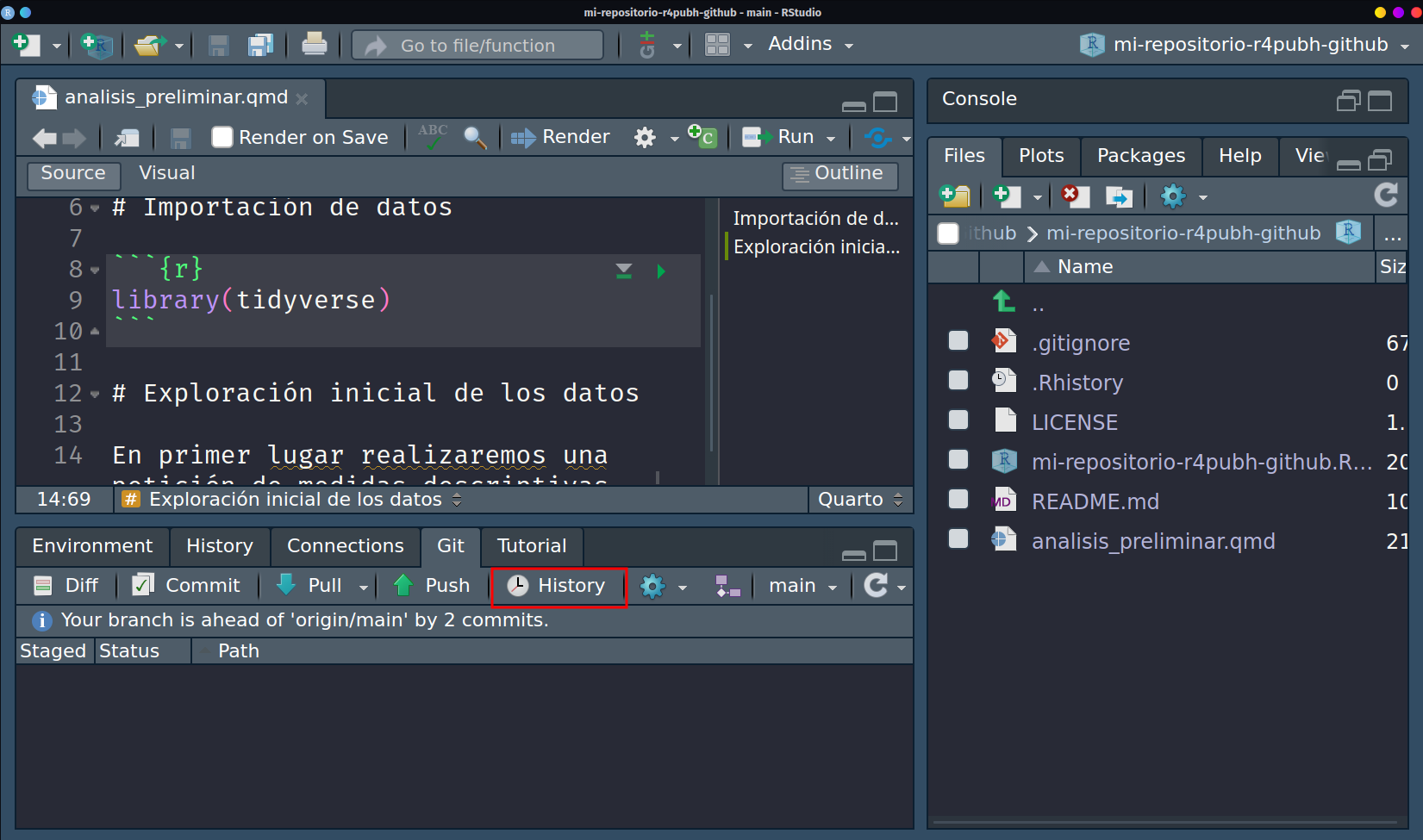
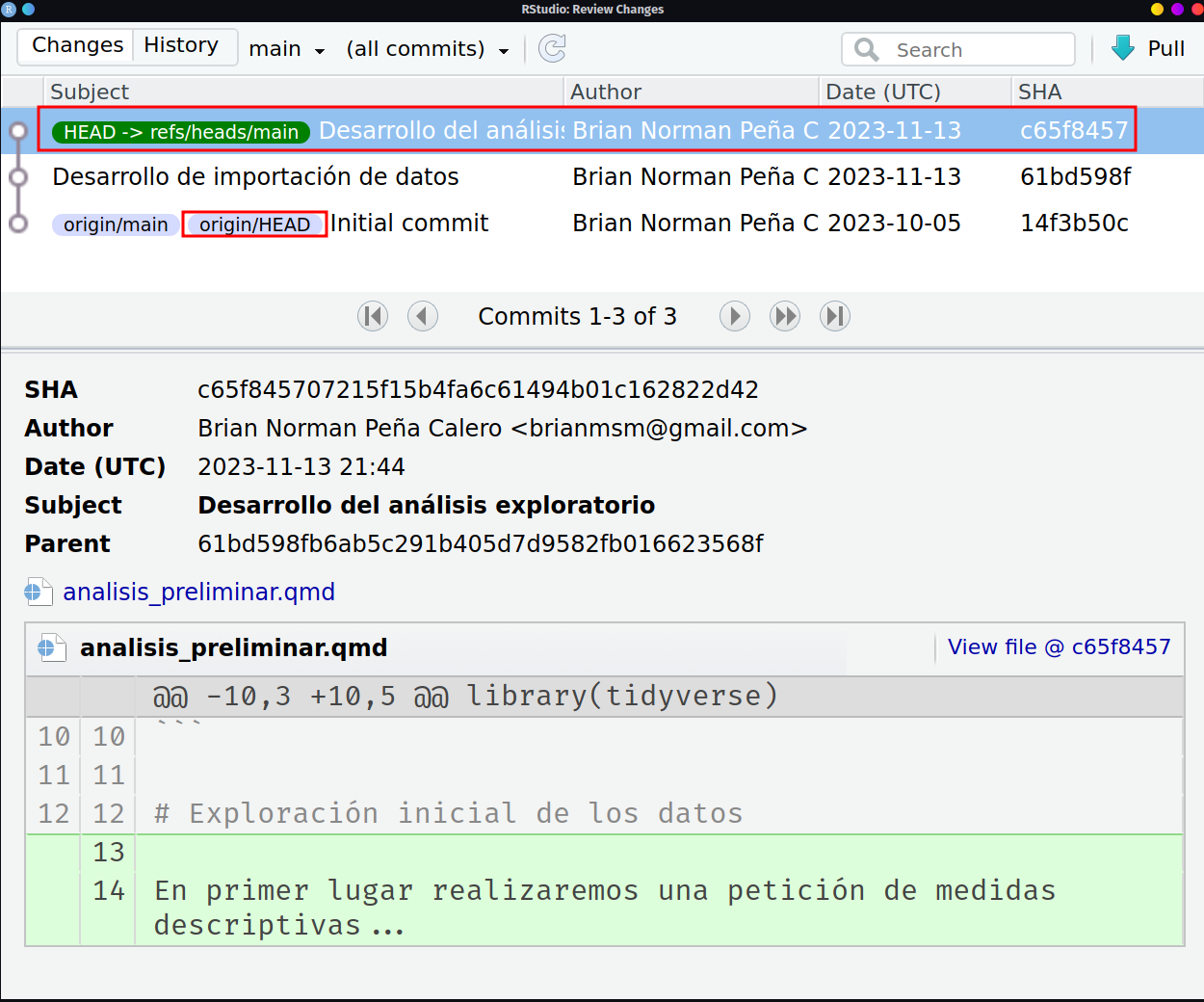
Una vez click ahí, podremos observar los 2 commits que hemos realizado desde la creación del proyecto, y aunque nuestro git local se encuentre con dichos cambios, podemos ver que la etiqueta de origin/HEAD aún permanece en el commit con mensaje Initial commit, es decir que nuestro repositorio en remoto solo tiene conocimiento del commit que se realizó durante su creación.
Para modificar esto y poder enviar nuestros cambios al repositorio, en el mismo panel git de Rstudio, daremos click en push que nos permitirá empujar nuestros cambios hacia el repositorio:
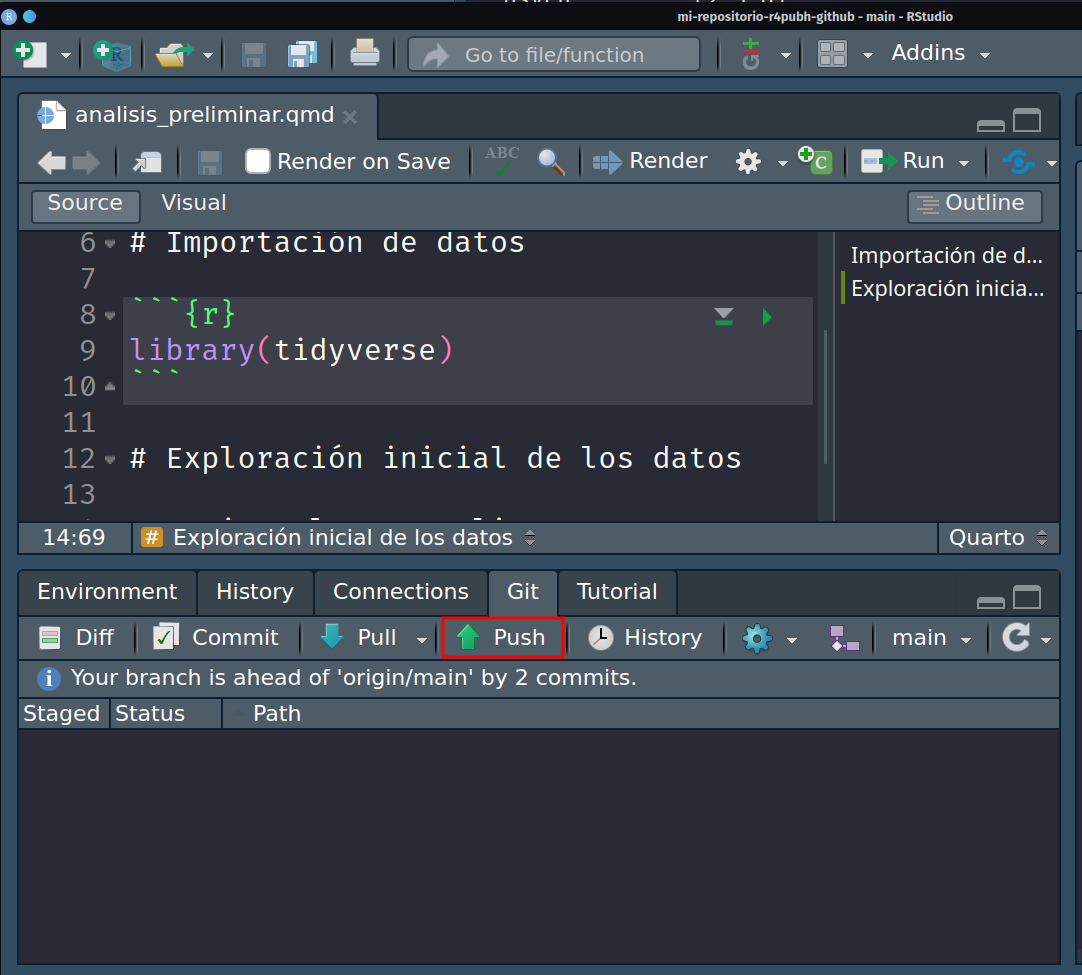
Una vez hecho ello, se abrirá un mensaje de que los archivos han sido enviados al servidor con la dirección en al que se encuentra alojado (github).
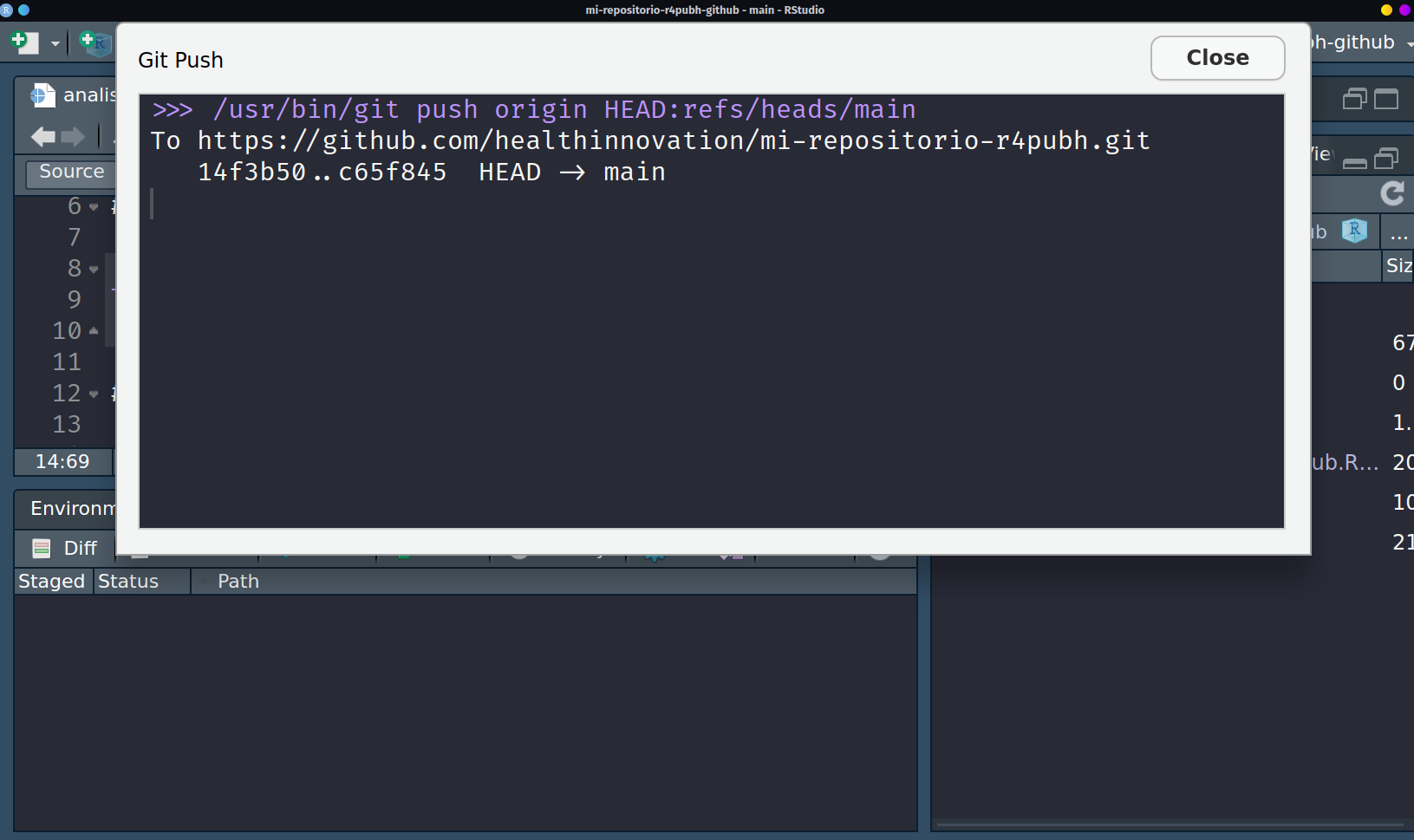
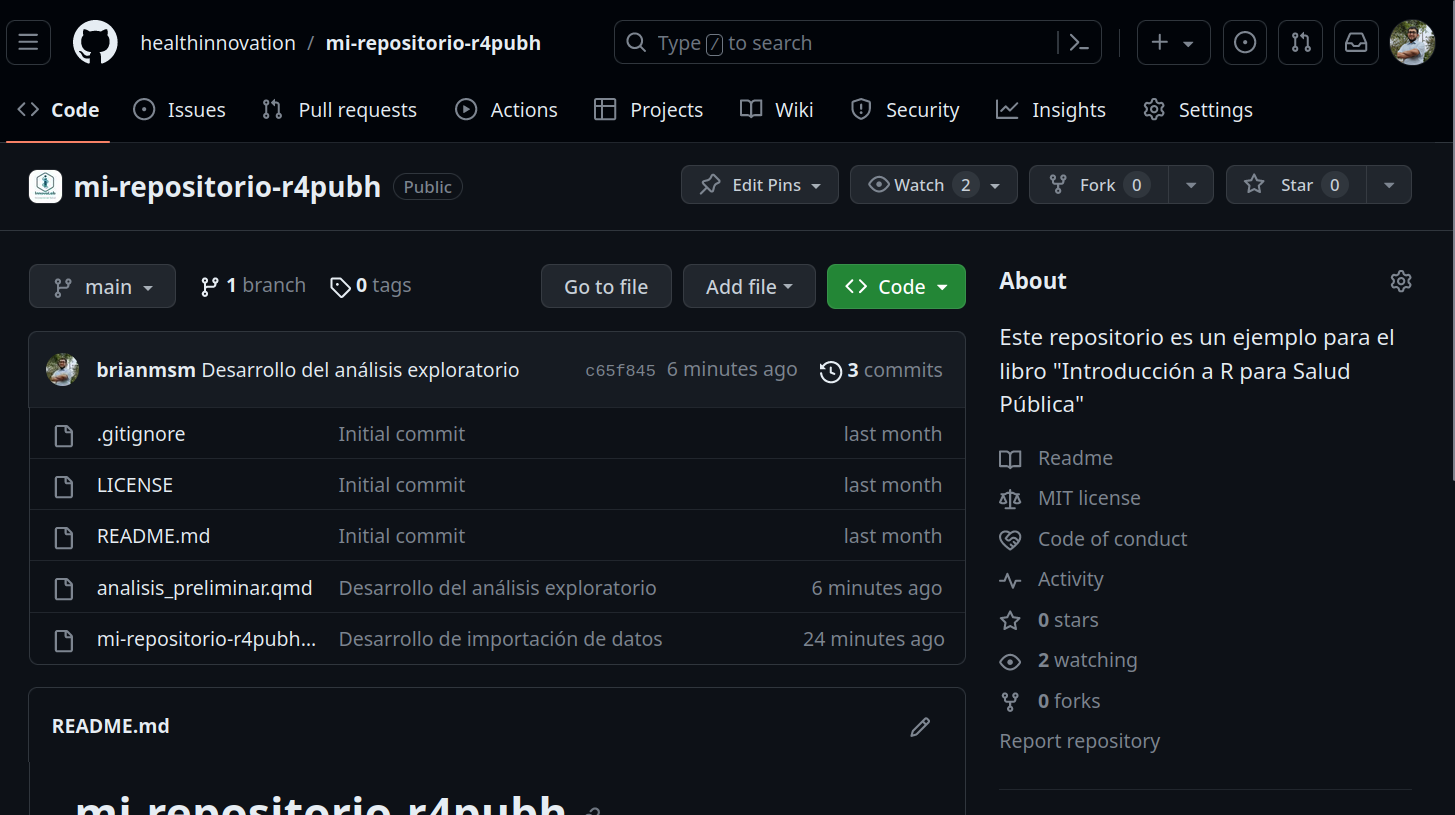
Y podemos verificare entrando al repositorio que efectivamente los cambios ya se pueden visualizar en remoto:
8.2.5 Aspectos adicionales
Hemos visto la funcionalidad básica de git y su manejo con Rstudio. Es posible manipular todos estos cambios, registros y envíos (push) desde la línea de comandos del sistema, u otros clientes que soporten la interacción con github como Github Desktop, Gitkraken, entre otros.
Además, hay algunos temas intermedios y avanzados que no se están tocando en este capítulo, y que son altamente deseables que un analista pueda aprender para tener un óptimo desenvolvimiento del menajeo de versiones en los proyectos de análisis:
Creación de ramas (branch)
Uso de pull-request
Creación de issues y resoluciones en ramas
Uso de forks en proyectos
Para quienes tengan un interés mayor en aprender algunos de esos tópicos, se recomienda el libro de Hester (s. f.) llamado Happy Git and GitHub for the useR que desarrolla mucho de estos puntos enfocados en proyectos de análisis de datos con R.